Не так давно наткнулась на серию статей про главный цикл в android, которые показались мне очень интересными. Поэтому сохраняю на память.
Пишем свой цикл
Основой любого приложения является его главный поток. На нём происходят все самые важные вещи: создаются другие потоки, меняется UI. Важнейшей его частью является цикл. Так как поток главный, то и его цикл тоже главный - в простонародье Main Loop.
Тонкости работы главного цикла уже описаны в Android SDK, а разработчики лишь взаимодействуют с ним. Поэтому, хотелось бы разобраться подробней, как работает главный цикл, для чего нужен, какие проблемы решает и какие у него есть особенности.
Вообще, лучший способ понять, как что-то работает - сделать это самому. Поэтому, прежде чем лезть в дебри Android SDK давайте попробуем написать свой цикл, правда без блэкджека и прочего. Наоборот, это будет минимально работоспособный цикл, но зато хорошо демонстрирующий основную логику, без лишней мишуры.
Как вообще работают программы
Но для начала, давайте разберёмся как вообще работают простые программы в Java.
С точки зрения системы - всё что есть у программы это просто метод main который она вызовет при старте и завершит процесс после его выполнения.
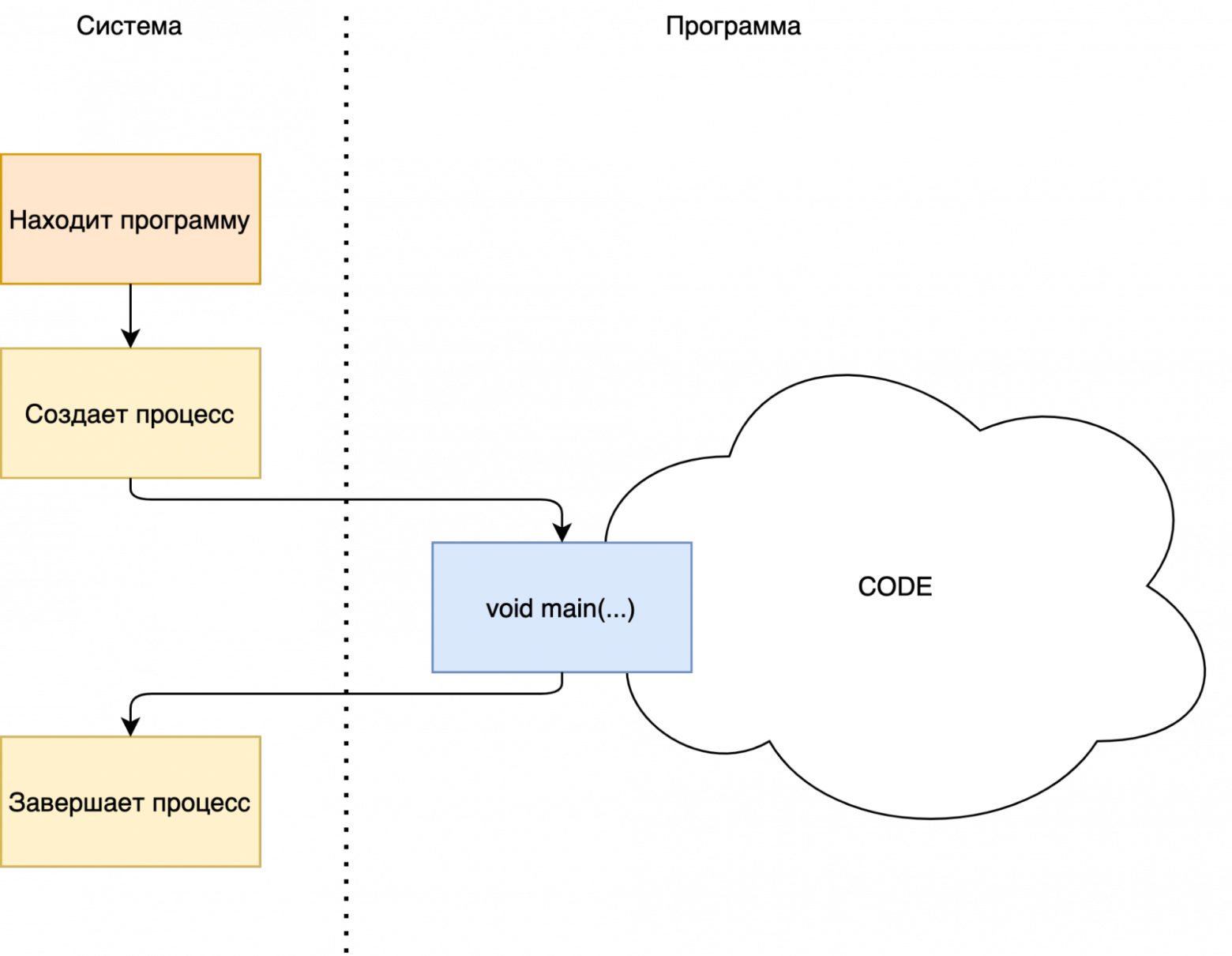
В коде это выглядит примерно так - у нас есть класс и внутри него метод main, который и вызовется системой. В данном случае мы просто выведем Hello World в консоль.
1
2
3
4
5
6
7
8
package myjavacode;
public class MyClass {
public static void main(String[] args) {
System.out.println("Hello World!");
}
}
Вместо вывода в лог мы можем открыть экран, выполнить сложную операцию или отправить запрос в сеть. Суть не изменится: после выполнения метода main - программа закроется. Программа или, если говорить в контексте Android - приложение, живёт пока что-то делает, затем просто завершается.
Почему так сделано? Изначально программы делались для командной строки, где основным методом взаимодействия является либо передача входных данных в виде аргументов, либо ввод данных пользователем в командную строку в процессе исполнения программы. После того как программа выполняла свою основную задачу ей просто не было смысла работать дальше, и такая программа завершала работу.
В программах использующих UI и в частности в Android приложениях - все не так. Приложение не закрывается как только сделает все что ему было предписано на старте. Оно терпеливо ждёт действий пользователя, кликов и прочего, и затем реагирует на них. Поэтому, приложения с UI должны жить и работать пока пользователь сам его не закроет (ну или пока приложение не упадет, или система сама его не закроет по причине нехватки памяти). Но вот проблема: как только последняя строчка метода main выполнится - приложение закроется само, так как посчитает, что оно сделало всё что нужно.
Как не дать приложению закрыться?
Для начала давайте разберёмся с тем, как же нам не дать приложению завершаться самостоятельно. Самый простой и самый действенный метод - (почти) бесконечный цикл. Проще всего его создать через обычный while.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public class MyClass {
private static boolean isAlive = true;
public static void main(String[] args) {
while(isAlive) {
doAction();
}
}
private static void doAction() {
}
}
По сути, мы просто добавили (почти) бесконечный цикл в котором вызывается метод doAction и теперь наше приложение уже не будет закрываться само, ведь цикл то бесконечный, а значит и приложению всегда есть что делать. Оно будет бесконечно выполнять метод doAction пока мы не попросим его наконец остановиться, переключив переменную isAlive в состояние false. Проблема только в том, что наше приложение пока ничего не делает. Метод doAction то пустой.
Заставляем приложение что-то делать
Теперь добавим возможность приложению выполнять какие-либо действия. Просто написать код всей программы в методе doAction не очень хороший вариант. В приложении могут быть сотни кнопок и текстовых полей на каждое из которых нужно написать свое действие. Если писать всё в одном методе то он довольно быстро превратится в нечитаемое чудовище размером в несколько десятков тысяч строк.
Поэтому воспользуемся функцией обратного вызова - в простонародье callback. Благо в Java уже есть интерфейс Runnable который хорошо для этого подходит. У него есть всего один метод run, который можно переопределить и написать туда своё действие.
Для того, чтобы понимать какое действие надо выполнить следующим поместим их в очередь. Пока для нее сгодится обычный ArrayList.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public class MyClass {
private static List<Runnable> availableActions = new ArrayList<>();
private static boolean isAlive = true;
public static void main(String[] args) {
while(isAlive) {
doAction();
}
}
private static void doAction() {
if (availableActions.size > 0) {
Runnable currentAction = availableActions.get(0);
currentAction.run();
availableActions.remove(currentAction);
}
}
}
Теперь в нашем цикле мы проверяем есть ли доступные действия. Если есть, то выполняем действие и удаляем его из списка доступных действий. Осталось только добавить какое-то действие в нашу очередь.
Для этого давайте представим, что у класса System есть возможность добавить слушатель на нажатия экрана вызвав метод - registerClickListener. В обратном вызове слушателя добавим какое-нибудь действие в очередь. Например, выведем в лог Click on screen.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
public class MyClass {
private static List<Runnable> availableActions = new ArrayList<>();
private static boolean isAlive = true;
public static void main(String[] args) {
System.registerClickListener((clickEvent) -> {
availableActions.add(() -> Log.d("Click on screen"));
});
while(isAlive) {
doAction();
}
}
private static void doAction() {
if (availableActions.size > 0) {
Runnable currentAction = availableActions.get(0);
currentAction.run();
availableActions.remove(currentAction);
}
}
}
Отлично! Теперь у нас есть приложение которое способно выводить сообщение в лог при нажатии на экран. Без цикла у нас бы ничего не вышло, ведь сразу после регистрации слушателя нажатий на экран, приложение закрылось бы и соответственно ни один клик не был бы обработан.
Новые действия могут добавляться в нашу очередь как от вызовов системы, так и внутри самих действий. То есть какое-то действие добавляет новое действие, а то добавляет ещё 5 новых и так до бесконечности.
Вроде всё хорошо, но есть один нюанс… Наше приложение теперь делает «что-то» постоянно. Даже когда у него нет доступных действий оно бесконечно проверяет не появились ли они. Тем самым оно постоянно загружает ядро процессора по максимуму, что явно не лучшим образом скажется на фоновых процессах, энергопотреблении и температуре самого процессора.
Заставляем приложение ничего не делать
Для того, чтобы дальнейшие действия выглядели менее абсурдными для тех кто разбирается - представим, что обратный вызов на нажатия на экран вызывается с какого-то отдельного потока системы.
Нам нужно указать, что если у нас пока нет доступных действий, то пора ничего не делать. Для этого воспользуемся стандартным методом wait() который заставляет текущий поток ждать и соответственно - бездействовать.
Так же, когда случится обратный вызов от нажатия на экран нам надо сказать нашему потоку, что пора поработать и проверить наличие доступных для выполнения действий. Для этого воспользуемся стандартным методом notify() который «разбудит наш поток».
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
public class MyClass {
private static List<Runnable> availableActions = new ArrayList<>();
private static boolean isAlive = true;
public static void main(String[] args) {
System.registerClickLister((clickEvent) -> {
availableActions.add(() -> Log.d("Click on screen"));
availableActions.notify();
});
while(isAlive) {
doAction();
}
}
private static void doAction() {
if (availableActions.size > 0) {
Runnable currentAction = availableActions.get(0);
currentAction.run();
availableActions.remove(currentAction);
} else {
availableActions.wait();
}
}
}
Теперь наше приложение не отжирает все доступные ресурсы, а спокойно ждёт, пока придёт следующее действие, чтобы его обработать. Как только все доступные для выполнения действия заканчиваются оно засыпает, а когда происходит клик и появляется новое действие - оно просыпается.
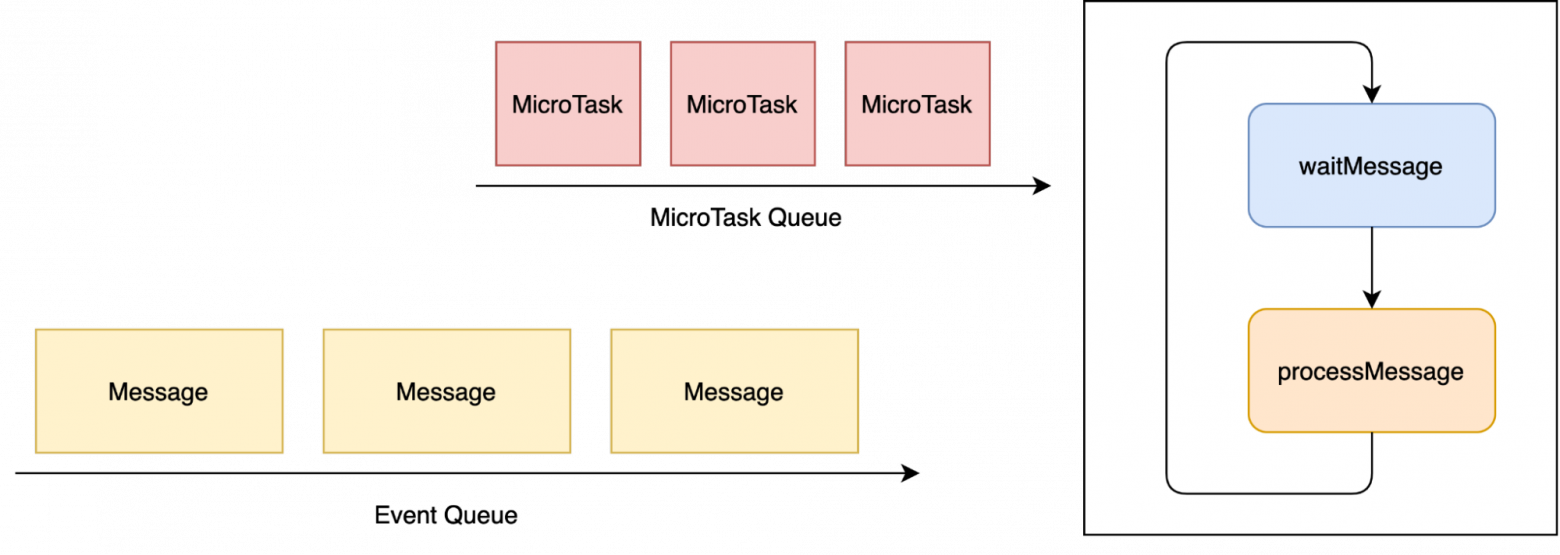
Самый главный цикл в жизни программы
Сам по себе подход с использованием цикла называется Event Loop (если вам больше нравится на русском - Цикл событий). Если же Event Loop обеспечивает работу главного потока - то он уже «поднялся», он не какой-то простой Event Loop, он - Main Loop (Главный цикл). По сути он является ядром всего приложения, обеспечивая его работу. Весь код выполняемый на главном потоке (Main Thread) проходит через него. Практически все приложения в которых есть UI (и не только они) используют его.
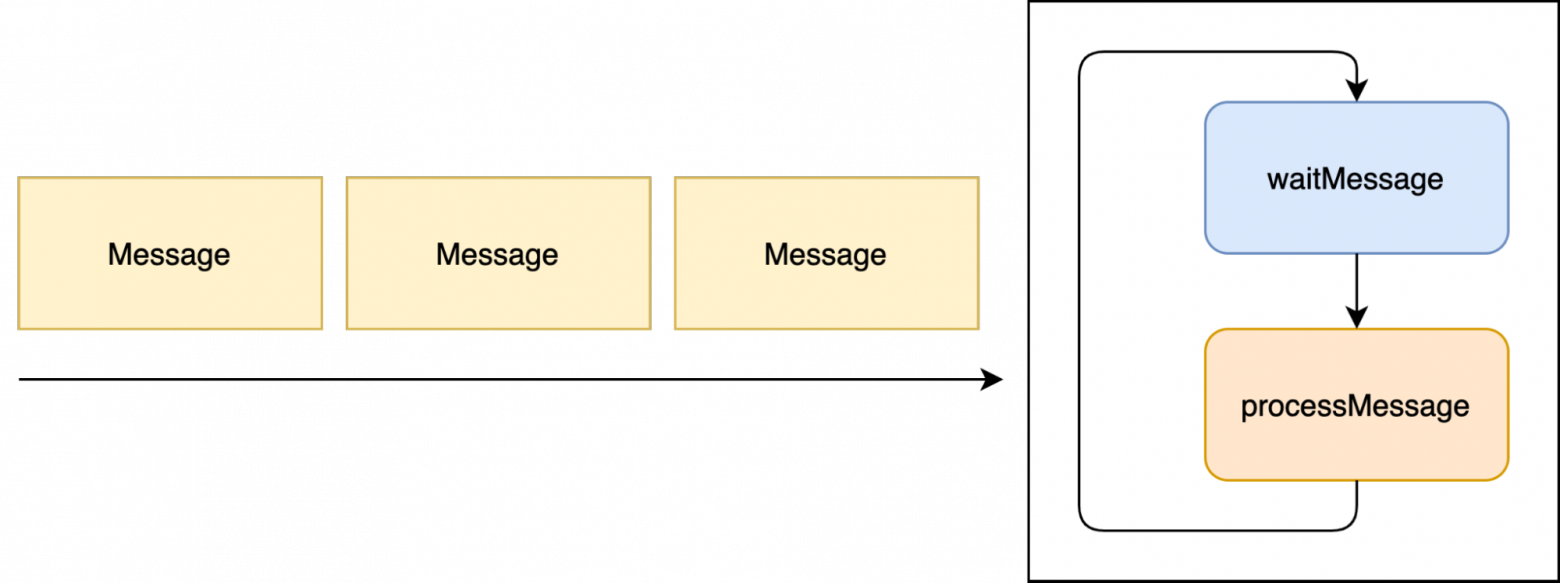
Вариантов реализации Main Loop множество, но нас сейчас интересует конкретно то - как это реализовано в Android. В целом у нас получился неплохой колхозный вариант Main Loop, но он не дает понимания всех нюансов работы главных циклов. Поэтому давайте вернёмся к коду на котором мы остановились и добавим немного комфортной городской среды в наш колхоз.
Распределяем ответственности по классам
В целом у нас написано что-то похожее на рабочий код. Приложение само не закрывается, ждёт команд от пользователя и умеет их выполнять. Но как-то всё не по принципам SOLID, особенно с буквой S (Single-Responsibility Principle) большие проблемы. Вся логика в одном классе и ни о каком разделении ответственности речи идти не может. Давайте попытаемся это исправить, да и в целом хочется накинуть новых возможностей.
Для начала давайте сделаем обёртку над Runnable и назовем её… к примеру Message.
Message
Для этого просто создадим новый класс Message. Одним из полей которого как раз и будет наш Runnable. Назовем его callback.
1
2
3
4
class Message {
Runnable callback;
public long when;
}
Дополнительно добавим еще одно поле when. Оно будет хранить значение времени в которое нужно выполнить действие. Ведь не всегда нужно выполнять что-то здесь и сейчас. Иногда, чтобы всё было хорошо, нужно подождать 500 миллисекунд. Для реализации такого механизма в поле when будет записываться время с момента старта приложения плюс время через которое должно произойти действие записанное в callback. Тоесть when = время с момента старта приложения + задержка для сообщения. Допустим я добавляю действие и хочу, чтобы оно выполнилось через 500 миллисекунд, а с момента старта приложения прошло 2000 миллисекунд, тогда в when у нас будет 2000 + 500 = 2500. Если же мне важно выполнить действие как можно скорее, то тогда в поле when надо записать 0.
Теперь давайте разберёмся с нашим ArrayList, который содержит действия.
ArrayList
Тут сразу стоп!!! Мы ведь добавили поле when, тем самым позволяя создавать отложенные сообщения, а следовательно у нас появятся сообщения, которые могут находится в очереди очень долго ожидая своего часа.
Может сложиться следующая ситуация: у меня есть список из трёх сообщений, первые два должны выполняться как можно скорее, а третье… допустим через час. При этом первое сообщение добавляет ещё 10 сообщений в нашу очередь, каждое из которых должно выполняться как можно скорее. Это значит, что их надо добавить в очередь сразу после второго сообщения. Получается вставка в середину списка, а как все знают у ArrayList с операцией вставки есть проблемы.
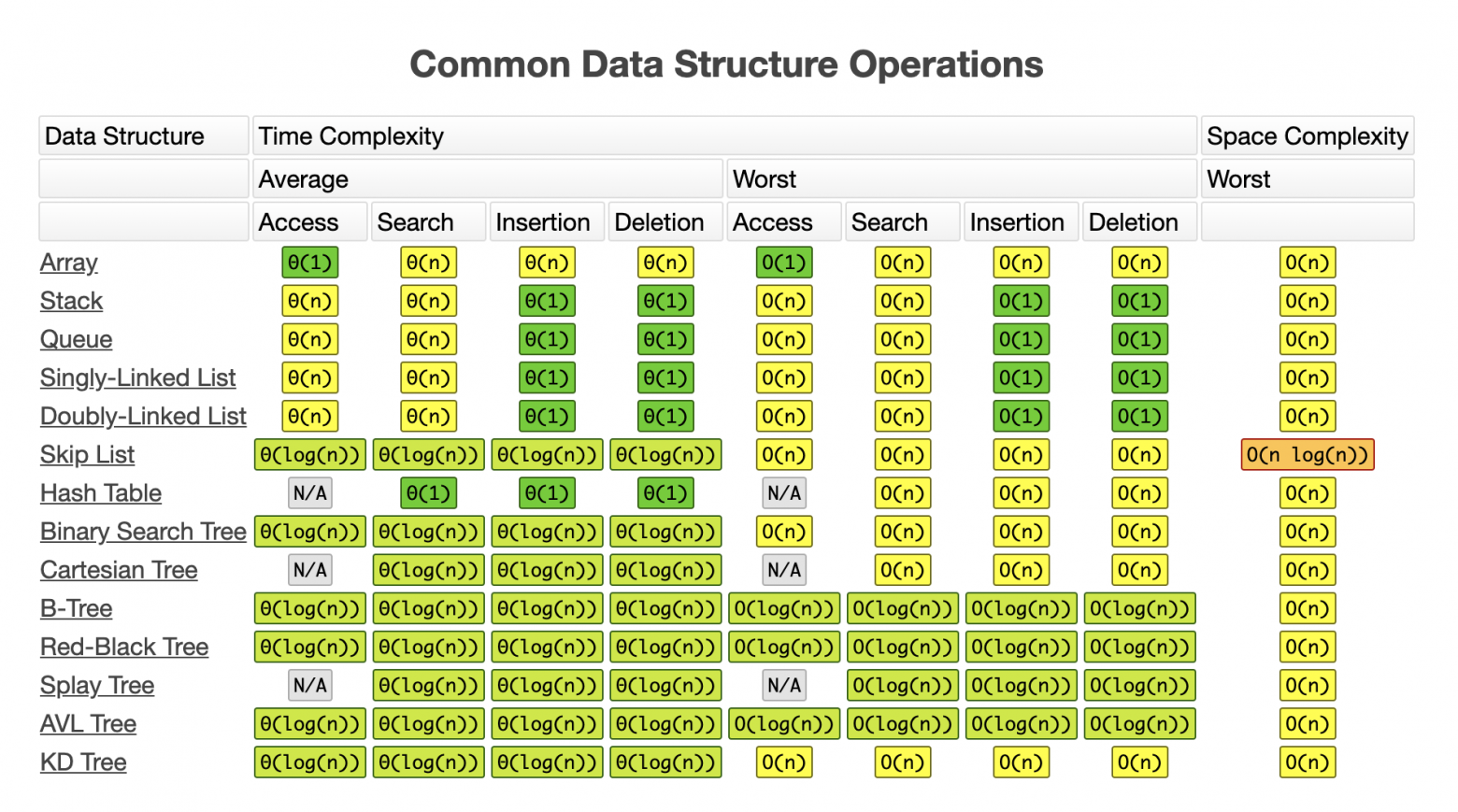
Вставка в ArrayList имеет сложность O(n), а значит, чем больше у нас будет сообщений в очереди, тем больше времени она будет занимать.
Поэтому хорошим решением будет заменить ArrayList на связный список, у которого сложность вставки O(1), а значит количество элементов не будет влиять на время операции. Правда у связного списка есть проблемы с временем доступа к произвольному элементу, но это не касается первого элемента. А нам как раз нужен доступ только к первому элементу.
После того как сообщение выполнит свою работу, оно станет ненужным. Поэтому двусвязный список тут не очень подходит, ведь придётся каждый раз при удалении первого сообщения обращаться и ко второму, чтобы удалить ссылку на первое. А вот односвязный список - вполне подходит. Проблема только в том, что в Java нет стандартной реализации односвязного списка. Не беда! Сделаем сами. Для этого просто добавим поле next типа Message в сам Message.
1
2
3
4
5
class Message {
Runnable callback;
public long when;
Message next;
}
Теперь у нас каждое сообщение содержит ссылку на следующее, таким образом формируя список. Если в поле next записан null, то это значит текущее сообщение является последним в списке.
Наш односвязный список готов и можно двигаться дальше.
Очередь сообщений
Теперь бы надо где-то прописать логику работы с сообщениями. Для этого создадим новый класс. Пусть будет MessageQueue. Это конечно не Queue в прямом понимании этого типа, так как у нас есть вставка в середину. С другой стороны - мы всегда берём для работы первое сообщение, так что называть класс MessageList еще более странная затея.
1
2
3
class MessageQueue {
Message messages;
}
Пока в классе у нас будет единственное поле messages со ссылкой на начало списка сообщений, то есть ближайшее сообщение которое мы планируем обработать. Соответственно если поле messages = null, то список пустой, а значит новых сообщений нет.
Возвращаем текущее сообщение
Теперь надо добавить метод который будет возвращать текущее сообщение. Для того, кто будет вызывать этот метод оно, по сути, будет следующим. Потому и назовем метод соответствующе - next.
1
2
3
4
5
6
7
8
9
10
11
12
13
class MessageQueue {
Message messages;
Message next() {
Message current = messages;
if (current == null) {
return null;
} else {
messages = current.next;
}
return current;
}
}
В нём все просто:
- берём текущее сообщение
- у него забираем ссылку на следующее за ним сообщение
- делаем его текущим.
Таким образом мы сделали текущим то сообщение, что было следующим, тем самым продвинув очередь. А то, что было текущим, возвращаем тому, кто вызвал этот метод.
Теперь нужно учесть, что сообщение имеет поле when, которое позволяет выполнить сообщение в указанное время, а значит сообщение не всегда нужно отдавать, оно ещё может быть не готово выполниться. Для этого добавим проверку сообщения по времени.
1
2
3
4
5
6
7
8
9
10
11
Message next() {
Message current = messages;
final long now = SystemClock.uptimeMillis();
if (current == null || now < current.when) {
return null;
} else {
messages = current.next;
return current;
}
}
Для этого берём время которое прошло с момента старта приложения и записываем в переменную now. Далее просто сравниваем now и время, когда сообщение в переменной current должно выполниться. Если now меньше, то сообщаем тем кто вызвал метод, что следующего сообщения как будто бы и нет.
Новое сообщение
Получать следующее сообщение мы научились, теперь надо научиться добавлять новое. Для это создадим метод enqueueMessage, который добавляет новое сообщение.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
boolean enqueueMessage(Message newMessage) {
if (newMessage == null) {
return false;
}
Message current = messages;
if (current == null) {
messages = newMessage;
} else {
Message previous;
while(true) {
previous = current;
current = current.next;
if (current == null) {
break;
}
}
previous.next = newMessage;
}
return true;
}
Внутри него сначала проверим есть ли у нас хоть одно запланированное действие. Если нет, то делаем новое сообщение первым в очереди. Если же есть, то пробежимся в цикле по нашей очереди, найдём последнее, то есть то, что имеет в поле next - null и добавим новое сообщение в самый конец, записав его в этот самый next.
Теперь нужно учесть, что enqueueMessage может вызываться с разных потоков, а это значит, что нам нужно синхронизировать добавление сообщений. Иначе может случиться плохая ситуация, когда два потока одновременно попробуют добавить сообщение и в лучшем случае мы получим потерю одного из сообщений, в худшем аварийное завершение программы.
Просто засунем код нашего метода в блок synchronized.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
boolean enqueueMessage(Message newMessage) {
if (newMessage == null) {
return false;
}
synchronized (this) {
Message current = messages;
if (current == null) {
messages = newMessage;
} else {
Message previous;
while(true) {
previous = current;
current = current.next;
if (current == null) {
break;
}
}
previous.next = newMessage;
}
}
return true;
}
А так же добавим synchronized в метод next, так как он тоже обращается к messages и опять же может случиться нечто нехорошее.
1
2
3
4
5
6
7
8
9
10
11
12
Message next() {
synchronized (this) {
Message current = messages;
final long now = SystemClock.uptimeMillis();
if (current == null || now < current.when) {
return null;
} else {
messages = current.next;
return current;
}
}
}
Теперь нужно учесть, что мы можем добавить новое сообщение в середину очереди. Для этого добавим сравнение сообщений по полю when когда ищем последнее сообщение. То есть теперь мы ищем не просто сообщение, у которого next равен null, но так же и смотрим, чтобы у следующего сообщения значение when было меньше чем у нового. Ну и соответственно из-за вставки в середину нам нужно заполнить поле next у нового сообщения.
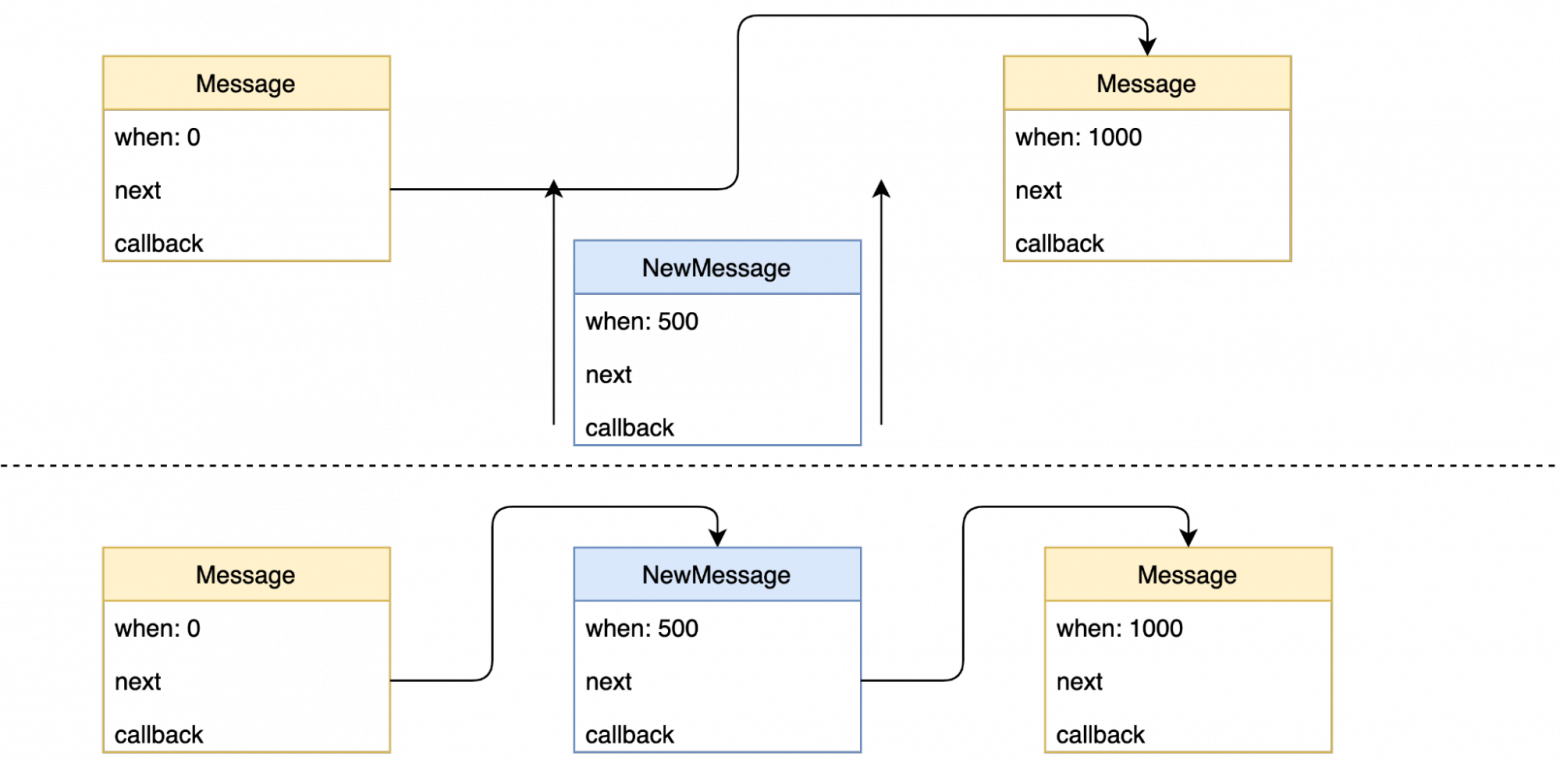
С точки зрения кода это будет выглядеть следующим образом:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
boolean enqueueMessage(Message newMessage) {
if (newMessage == null) {
return false;
}
synchronized (this) {
Message current = messages;
if (current == null) {
messages = newMessage;
} else {
Message previous;
while(true) {
previous = current;
current = current.next;
if (current == null || newMessage.when < current.when) {
break;
}
}
newMessage.next = previous.next;
previous.next = newMessage;
}
}
return true;
}
С очередью сообщений пока всё. Теперь пора переработать сам цикл.
Запускаем цикл
Заводим новый класс и называем его Looper. В нём у нас содержится очередь сообщений (MessageQueue), переменная isAlive, которая отвечает за то, продолжать ли приложению работать, а также два метода:
loop- в котором запускается и крутится наш циклshutdown- который переключаетisAliveвfalse, тем самым останавливая обработку сообщений и завершая приложение.
Давайте присмотримся к нашему основному методу loop поближе.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
class Looper {
private static Looper instance = new Looper();
final MessageQueue messageQueue;
private static boolean isAlive = true;
public Looper() {
messageQueue = new MessageQueue();
}
public static void loop() {
Looper currentInstance = instance;
while (isAlive) {
Message nextMessage = currentInstance.messageQueue.next();
if (nextMessage != null ) {
nextMessage.callback.run();
} else {
try {
instance.messageQueue.wait();
} catch (InterruptedException e) {
}
}
}
}
public static void shutdown() {
isAlive = false;
}
}
В нём мы получаем объект Looper и запускаем уже привычный нам бесконечный цикл, в котором запрашиваем новое сообщение у MessageQueue. Если сообщение есть, то выполняем действие, если же нет, то засыпаем.
Но уснуть то мы уснули, а когда же просыпаться? Нужно теперь куда-то добавить метод notify. По хорошему это надо делать там, где у нас добавляется новое сообщение, а происходит это внутри метода MessageQueue.enqueueMessage. Но вот засыпать в одном классе, а просыпаться в другом - идея так себе, ведь это будет сложно контролировать.
Также можно заметить, что мы не очень хорошо работаем с сообщениями которые собирались выполнить в определенное время и заполнили им поле when. Да, мы не выполним действие сообщения раньше времени за счёт проверки внутри MessageQueue, но мы можем проспать его выполнение, если у нас не будут поступать новые сообщения. Ведь спим мы пока не придёт новое сообщение и на самом деле маловероятно, что придёт оно именно в тот момент, когда надо будет выполнить сообщение по времени. Обе эти проблемы можно решить переносом ожидания нового сообщения внутрь MessageQueue.
Переносим ожидание в MessageQueue
Давайте сделаем так, чтобы мы гарантированно отдавали сообщение в методе next, а если сообщения нет, то дожидаемся его.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
Message next() {
int nextWaitTime = -1;
while (true) {
try {
if (nextWaitTime >= 0) {
wait(nextWaitTime);
}
} catch (InterruptedException e) {
}
synchronized (this) {
Message current = messages;
if (current != null) {
final long now = SystemClock.uptimeMillis();
if (now < current.when) {
nextWaitTime = (int) (current.when - now);
} else {
messages = current.next;
return current;
}
} else {
nextWaitTime = 0;
}
}
}
}
Также внутри метода next появился цикл, который отвечает за ожидание сообщения. В нём мы проверяем есть ли сообщения, если нет - то спим пока не вызовут notify. Если есть, то смотрим нужно ли сейчас выполнять действие текущего сообщения. Если да, то возвращаем сообщение, если же нет, то засыпаем пока не придёт время выполнить действие текущего сообщения.
В метод enqueueMessage же добавим вызов notify, чтобы пробудить наш цикл в методе next.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
boolean enqueueMessage(Message newMessage) {
if (newMessage == null) {
return false;
}
synchronized (this) {
Message current = messages;
if (current == null) {
messages = newMessage;
} else {
Message previous;
while (true) {
previous = current;
current = current.next;
if (current == null || newMessage.when < current.when) {
break;
}
}
newMessage.next = previous.next;
previous.next = newMessage;
}
notify();
}
return true;
}
Ну и напоследок в самом Looper уберём ожидание. Теперь он просто выполняет действия сообщений.
1
2
3
4
5
6
7
public static void loop() {
Looper currentInstance = instance;
while (isAlive) {
Message nextMessage = currentInstance.messageQueue.next();
nextMessage.callback.run();
}
}
Общая схема
Общая логика работы получилась такой:
- Система запускает наш процесс, что в итоге ведёт к вызову метода
loopуLooper. Looperвнутри себя обращается к методуnextуMessageQueueза новым сообщением.MessageQueueвидя, что сообщений пока нет - останавливает текущий поток с помощью методаwait.- Система кидает нам какое-нибудь событие, например клик на экран, что в итоге добавляет новое сообщение в нашу очередь сообщений через метод
enqueueMessageуMessageQueueи будит текущий поток. - Метод
nextуMessageQueueпросыпается и видит что у него появилось новое сообщение. - Это новое сообщение
MessageQueueвозвращается вLooper. Looperпросто выполняетcallbackиз сообщения.- Обратно к пункту 2.
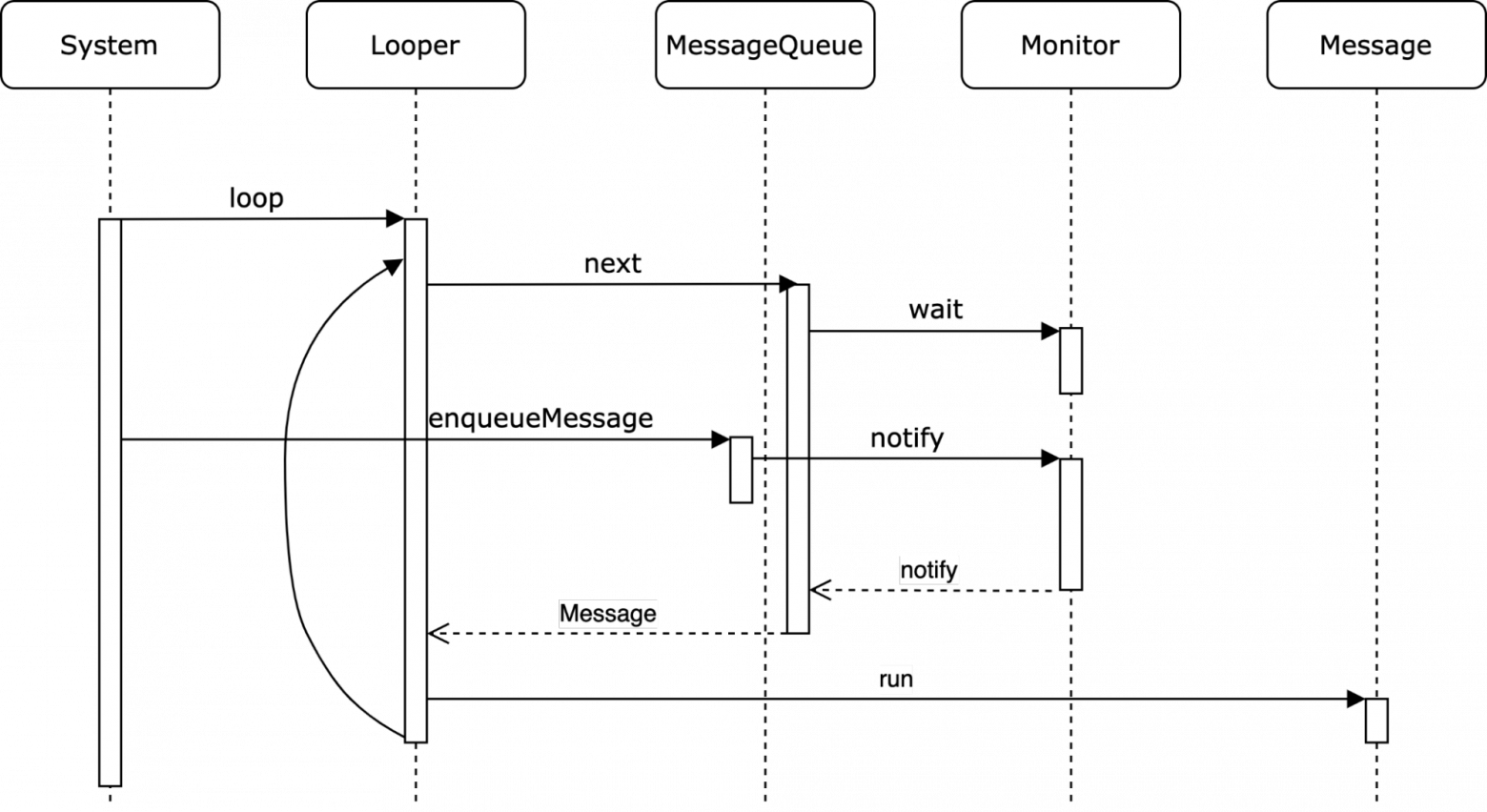
Отлично! В итоге у нас вполне рабочий цикл событий. Даже что-то близкое к тому, как все устроено в Android, но в Android классах кода куда больше. Например, в нашем Looper 25 строк, а в Android 493, правда это с учётом JavaDoc. Всё потому, что Looper, Message, MessageQueue обладают в Android SDK дополнительными возможностями.
Android SDK
Разобравшися с тем, что такое главный цикл и как он работает, давайте теперь разберёмся как Main Loop устроен в Android SDK. Разбираться будем в контексте Android SDK версии 30.
Looper
Начнём мы с самого главного - Looper. Напомню, что этот класс отвечает за сам цикл и его работу. Далее в рассуждениях я буду отталкиваться от того, что вы прочли первую часть и/или понимаете общую логику работы главного цикла. Приступим.
Может быть создан для любого из потоков и только один
Первое, что бросается в глаза - приватный конструктор.
1
2
3
4
private Looper(boolean quitAllowed) {
mQueue = new MessageQueue(quitAllowed);
mThread = Thread.currentThread();
}
Создать Looper можно только используя метод prepare.
1
2
3
4
5
6
7
8
9
10
11
12
static final ThreadLocal<Looper> sThreadLocal = new ThreadLocal<Looper>();
public static void prepare() {
prepare(true);
}
private static void prepare(boolean quitAllowed) {
if (sThreadLocal.get() != null) {
throw new RuntimeException("Only one Looper may be created per thread");
}
sThreadLocal.set(new Looper(quitAllowed));
}
При вызове публичного метода prepare вызывается его приватная реализация. Она принимает в себя параметр quitAllowed. Он будет true, если для данного Looper есть возможность завершиться во время работы приложения. Для главного потока этот параметр всегда будет false, так как если завершится главный поток, то завершится и приложение. Для побочных же потоков этот параметр всегда равен true.
Также в методе prepare можно заметить обращение к полю sThreadLocal типа ThreadLocal. Что же это такое?
ThreadLocal это такое хранилище, в котором для каждого из потоков будет хранится свое значение. Допустим я из потока 1 кладу в это хранилище true, затем если я обращусь из этого же потока к хранилищу - я получу true. Но если я обращусь к этому хранилищу из другого потока, то мне вернется null, так как для этого потока значение еще не было записано.
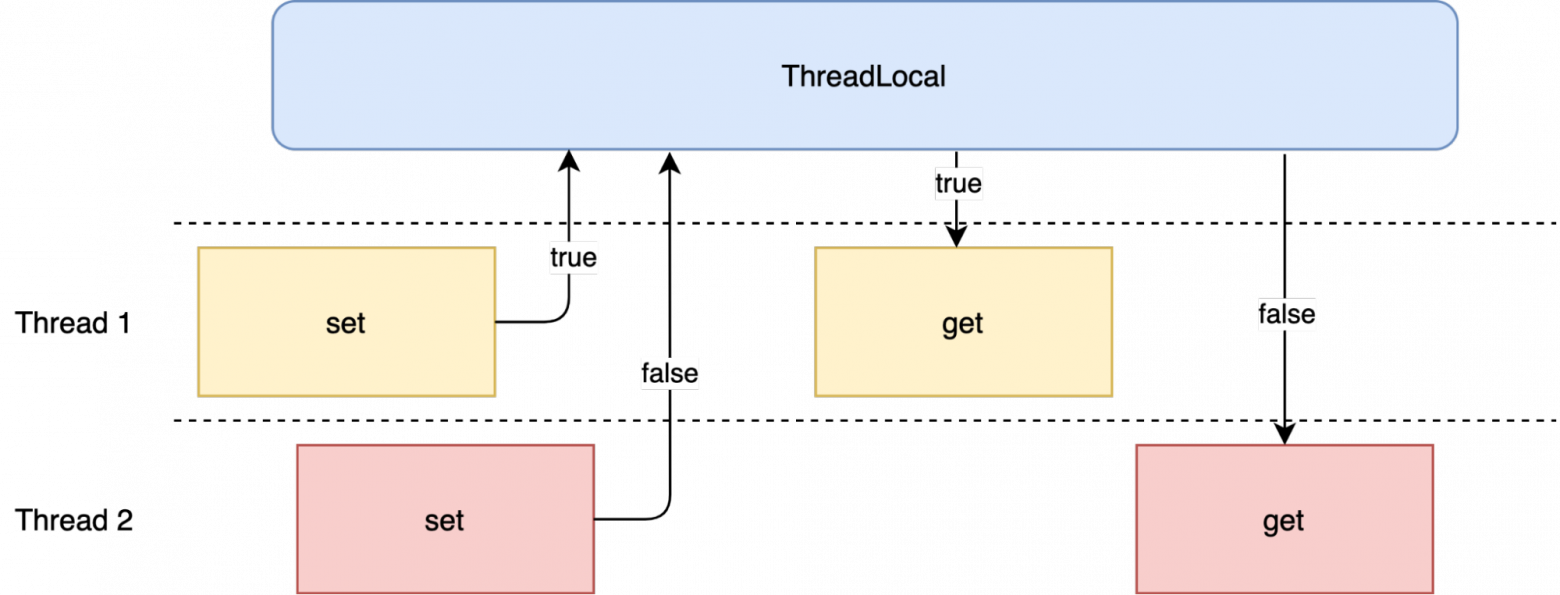
Looper использует этот механизм вкупе с приватным конструктором для того, чтобы обеспечить уникальность Looper для каждого из потоков. Внутри метода prepare с помощью ThreadLocal он сначала проверяет был ли уже создан Looper для текущего потока, если это так, то бросает исключение которое скажет о том, что негоже создавать несколько Looper для одного потока. Если же Looper для текущего потока еще не был создан, то он создает новый Looper и сразу же записывает его в ThreadLocal.
Для получения экземпляра Looper, созданного в методе prepare, есть метод myLooper. Он просто каждый раз обращается к sThreadLocal для получения значения для текущего потока.
1
2
3
public static Looper myLooper() {
return sThreadLocal.get();
}
С такой логикой Looper можно создать для любого из потоков, пользоваться и при этом точно знать, что для данного потока Looper только один. Допустим у нас есть 5 потоков и каждый из них создает и обращается к Looper. В итоге у нас будет создано 5 экземпляров Looper, но при обращении к Looper.myLooper каждый из потоков будет получать свой уникальный экземпляр.
Главный среди равных
Правда тут появляется вопрос - если Looper может быть несколько, то какой из них является главным циклом? Ведь я могу создать несколько потоков, для каждого из них создать Looper, то как потом другим программистам понять кто же из них главный и куда им слать сообщения? Создатели Android подумали так же. Поэтому в Looper есть следующий код:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
private static Looper sMainLooper;
public static void prepareMainLooper() {
prepare(false);
synchronized (Looper.class) {
if (sMainLooper != null) {
throw new IllegalStateException("The main Looper has already been prepared.");
}
sMainLooper = myLooper();
}
}
public static Looper getMainLooper() {
synchronized (Looper.class) {
return sMainLooper;
}
}
Отдельный метод prepareMainLooper как раз занимается тем, что создаёт Looper для текущего потока и записывает его в отдельное статическое поле sMainLooper, тем самым как-бы объявляя его главным. Теперь если кто-то попробует вызвать prepareMainLooper с другого потока, то будет брошено исключение, которое скажет нам, что главный вообще-то может быть только один.
Ещё у главного потока есть свой отдельный getter - getMainLooper, ведь обращение к главному циклу может понадобиться где угодно. Таким образом, разработчики всегда будут знать кто тут главный Looper.
Теперь давайте ближе взглянем на особенности самого цикла, а значит на метод loop.
Логирование
Первое что бросается в глаза в методе loop, это то, что у нас вместо цикла while используется for с двумя точками с запятой. Такой подход вроде как производительнее.
Также можно заметить, что остановка бесконечного цикла делается не с помощью переключения отдельной переменной isAlive, а с помощью получения null от MessageQueue.next.
1
2
3
4
5
6
7
8
9
10
public static void loop() {
..................
for (;;) {
Message msg = queue.next();
if (msg == null) {
return;
}
}
}
Куда более интересное отличие, что в Looper из Android SDK у нас появляется логирование. Для него используется класс под названием Printer. По сути его единственной функцией является вывод сообщения с помощью метода println.
Инициализированный объект Printer хранится в поле mLogging, то есть у каждого из Looper может быть свой личный Printer. Выставляется Printer через отдельный сеттер. Если же Printer не задать, то и логирования не будет.
1
2
3
4
5
private Printer mLogging;
public void setMessageLogging(@Nullable Printer printer) {
mLogging = printer;
}
Внутри самого метода loop Printer используется трижды:
- в первый раз когда мы принимаем сообщение. Ссылка из поля
mLoggingзаписывается вfinalпеременнуюlogging. Это нужно, чтобы не было ситуаций когда во время обработки сообщения мы сменилиPrinterв полеmLoggingи логирование по одному сообщению произошло в разные места; - во второй раз когда он сообщает нам о том, что началась обработка сообщения и выводит информацию о самом сообщении;
- в третий раз когда он сообщает нам о том, что обработка сообщения завершена и выводит информацию о самом сообщении.
1
2
3
4
5
6
7
8
9
final Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
..................
if (logging != null) {
logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
}
Но логирование не является единственным способом отслеживания работы Looper. Дополнительно используется класс Trace. Он нужен для трассировки стека методов через SysTrace. С помощью SysTrace мы в Profiler из Android Studio можем просматривать этот самый стек и время исполнения каждого из методов в нем. Для этого, перед тем как начнет обрабатываться новое сообщение вызывается Trace.traceBegin и когда обработка сообщения завершится Trace.traceEnd.
1
2
3
4
5
6
7
if (traceTag != 0 && Trace.isTagEnabled(traceTag)) {
Trace.traceBegin(traceTag, msg.target.getTraceName(msg));
}
..................
if (traceTag != 0) {
Trace.traceEnd(traceTag);
}
Но это ещё не все методы слежки.
Подсчёт времени
Looper считает время доставки и обработки сообщений и если это время больше ожидаемого, то он сообщит нам об этом. Это может понадобиться в поисках источников фризов и лагов. Допустим у нас экран 60 Гц, значит желательно, чтобы каждое сообщение обрабатывалось не более 1000 / 60 = 16,6 мс (на самом деле нужно меньше, но не суть), иначе главный поток не успеет подготовить данные для отрисовки и у нас используется прошлый кадр. Из-за этого будет казаться будто бы изображение зависло, а значит интерфейс перестанет быть плавным.
Для этого у нас имеется два поля типа long: mSlowDeliveryThresholdMs, отвечающий за время доставки сообщения, и mSlowDispatchThresholdMs, отвечающий за время обработки сообщения.
1
2
3
4
5
6
7
private long mSlowDispatchThresholdMs;
private long mSlowDeliveryThresholdMs;
public void setSlowLogThresholdMs(long slowDispatchThresholdMs, long slowDeliveryThresholdMs) {
mSlowDispatchThresholdMs = slowDispatchThresholdMs;
mSlowDeliveryThresholdMs = slowDeliveryThresholdMs;
}
Выставляем mSlowDispatchThresholdMs равным 16 и Looper сам будет уведомлять нас о всех сообщениях которые обрабатывались дольше этого времени и соответственно являются причиной подвисания.
Для выставления значений этих полей создан отдельный метод setSlowLogThresholdMs. Эти поля всегда выставляются парой.
Также есть возможность задать это время с помощью системной переменной. Имя которой формируется по следующему принципу: log.looper.<”идентификатор процесса”>.<”имя потока, в нашем случае это будет main”>.slow.
1
2
3
4
5
final int thresholdOverride =
SystemProperties.getInt("log.looper."
+ Process.myUid() + "."
+ Thread.currentThread().getName()
+ ".slow", 0);
Теперь посмотрим как это всё работает внутри метода loop.
1
2
3
4
5
6
7
8
9
10
11
long slowDispatchThresholdMs = me.mSlowDispatchThresholdMs;
long slowDeliveryThresholdMs = me.mSlowDeliveryThresholdMs;
if (thresholdOverride > 0) {
slowDispatchThresholdMs = thresholdOverride;
slowDeliveryThresholdMs = thresholdOverride;
}
final boolean logSlowDelivery = (slowDeliveryThresholdMs > 0) && (msg.when > 0);
final boolean logSlowDispatch = (slowDispatchThresholdMs > 0);
final boolean needStartTime = logSlowDelivery || logSlowDispatch;
final boolean needEndTime = logSlowDispatch;
Выглядит как-то путано, не правда ли? Сначала значение полей записываются в локальные переменные. Затем проверяется, не было ли задано ограничение с помощью системной переменной, если это так, то берётся именно оно. Если оба значения для времени доставки и обработки больше нуля, то метод loop понимает, что время начать считать.
Далее формируются два значения: начала и окончания. Если с обработкой всё понятно, то для подсчёта времени доставки в качестве времени начала выступает ожидаемое время начала обработки, а в качестве времени окончания используется время реального начала обработки.
После того как обработка сообщения завершится вызывается статический метод showSlowLog отдельно для времени доставки и отдельно для времени обработки.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
private static boolean showSlowLog(
long threshold,
long measureStart,
long measureEnd,
String what,
Message msg
) {
final long actualTime = measureEnd - measureStart;
if (actualTime < threshold) {
return false;
}
Slog.w(TAG, "Slow " + what + " took " + actualTime + "ms "
+ Thread.currentThread().getName() + " h="
+ msg.target.getClass().getName() + " c=" + msg.callback + " m=" + msg.what);
return true;
}
В самом методе всё довольно просто - из времени окончания вычитается время начала, таким образом получается длительность обработки или доставки. Если эта длительность больше чем ожидаемая, то происходит вывод в лог информации о сообщении.
Интересный момент тут в том, что логирование происходит с помощью класса Slog, а не обычного Log. Slog - это специальный класс, который выводит логи от имени системы. Так что, имейте ввиду, что если установить фильтр по имени вашего процесса в logcat, то вы не увидите этих сообщений.
Наблюдатели и try/catch
И это ещё не все способы наблюдения за Looper. До этого информация выводилась либо в лог, либо в SysTrace. Но что если надо следить за Looper прямо в коде? Для этого используется внутренний interface Looper - Observer.
1
2
3
4
5
6
7
8
public interface Observer {
Object messageDispatchStarting();
void messageDispatched(Object token, Message msg);
void dispatchingThrewException(Object token, Message msg, Exception exception);
}
Он содержит в себе методы наблюдения за стартом обработки сообщения, за окончанием обработки сообщения и за вероятным исключением при обработке сообщения. Последний метод может понадобиться, чтобы как-то использовать исключение, которое привело к падению приложения, например, отправить информацию о нём на удалённый сервер, как это делает Firebase Crashlytics.
Сам Observer хранится статической переменной sObserver, то есть наблюдатель выставляется сразу для всех экземпляров Looper. Выставляется он через отдельный сеттер.
1
2
3
4
5
private static Observer sObserver;
public static void setObserver(@Nullable Observer observer) {
sObserver = observer;
}
Сама логика вызова методов Observer довольно простая.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
Object token = null;
if (observer != null) {
token = observer.messageDispatchStarting();
}
long origWorkSource = ThreadLocalWorkSource.setUid(msg.workSourceUid);
try {
msg.target.dispatchMessage(msg);
if (observer != null) {
observer.messageDispatched(token, msg);
}
dispatchEnd = needEndTime ? SystemClock.uptimeMillis() : 0;
} catch (Exception exception) {
if (observer != null) {
observer.dispatchingThrewException(token, msg, exception);
}
throw exception;
} finally {
ThreadLocalWorkSource.restore(origWorkSource);
if (traceTag != 0) {
Trace.traceEnd(traceTag);
}
}
В момент обработки сообщения внутри метода loop проверяется - есть ли сейчас наблюдатель, если наблюдатель имеется, то у него вызывается метод messageDispatchStarting. Методы messageDispatched и dispatchingThrewException вызываются в соответствующих местах.
Можно заметить, что обработка сообщения обёрнута в try-catch-finally. Это необходимо, чтобы в случае ошибки правильно отработали методы трассировки SysTrace, а так же вызов метода dispatchingThrewException у наблюдателя. И лишь потом будет брошено исключение, которое и завершит наше приложение.
Это пожалуй все интересные особенности класса Looper в Android SDK.
ActivityThread
Теперь давайте рассмотрим, где же всё-таки у нас идёт работа с самим Looper. А происходит это всё также в методе main и находится он в классе ActivityThread.
1
2
3
4
5
6
7
8
9
10
11
12
13
public static void main(String[] args) {
..................
Looper.prepareMainLooper();
..................
if (false) {
Looper.myLooper().setMessageLogging(new
LogPrinter(Log.DEBUG, "ActivityThread"));
}
..................
Looper.loop();
throw new RuntimeException("Main thread loop unexpectedly exited");
}
В нём сначала вызывается метод prepareMainLooper. Далее выставляется реализация Printer. И под самый конец метода вызывается метод loop, запускающий главный цикл. Последней строкой этого метода бросается исключение. Таким образом, как только цикл завершится, то и завершится весь процесс.
Если хотите поподробнее узнать о том как запускается процесс в андроид, то рекомендую посмотреть эту статью.
MessageQueue
Теперь рассмотрим какими особенностями обладает MessageQueue - класс? отвечающий за работу очереди сообщений в Android SDK.
Main Thread не ждет
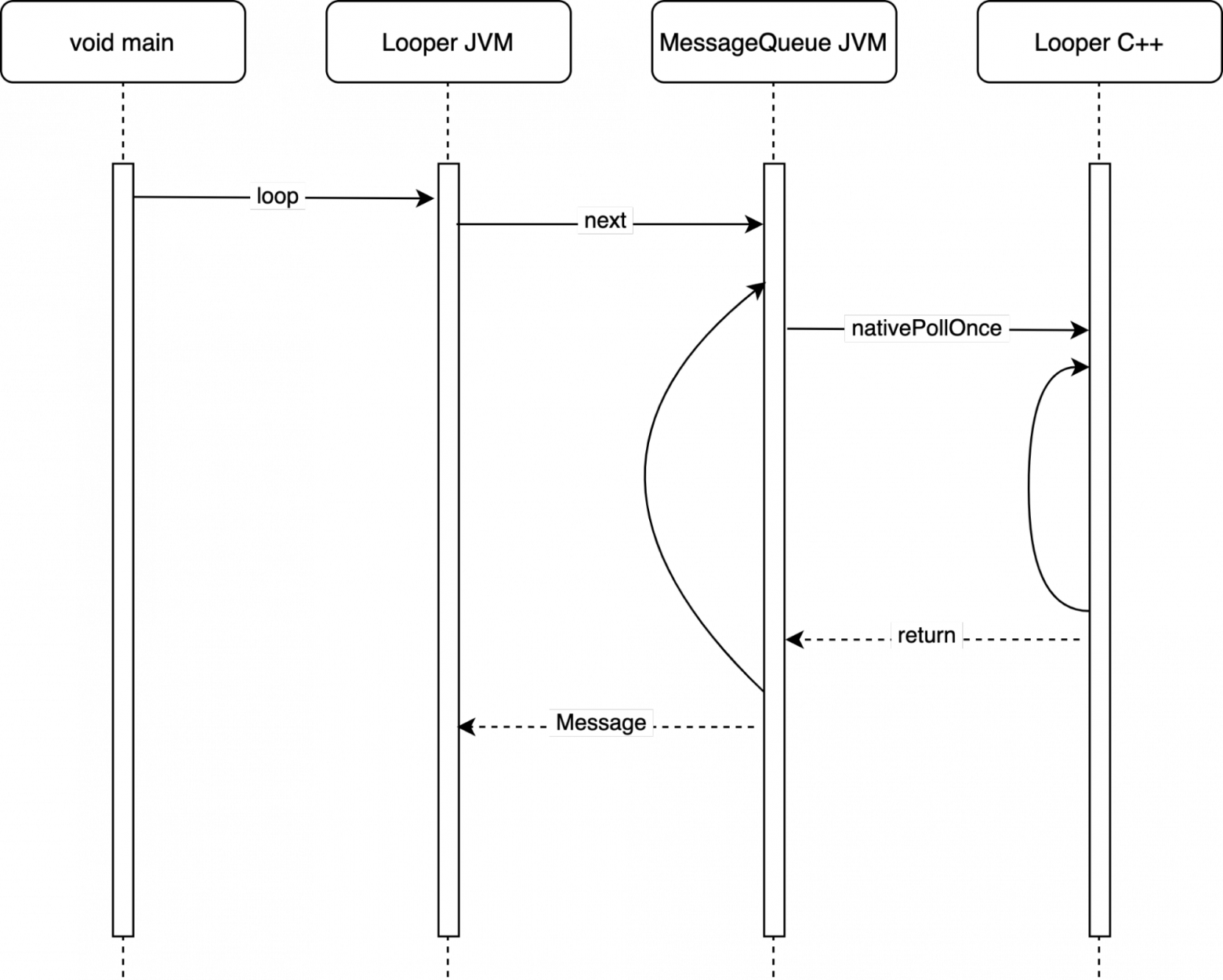
Первая особенность MessageQueue заключается в том, что вместо стандартных методов из Java wait и notify используются нативные методы nativePollOnce и nativeWake.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
private long mPtr;
private native void nativePollOnce(long ptr, int timeoutMillis);
private native static void nativeWake(long ptr);
Message next() {
..................
nativePollOnce(mPtr, nextPollTimeoutMillis);
..................
}
boolean enqueueMessage(Message msg, long when) {
..................
nativeWake(mPtr);
..................
}
Когда мы пытаемся запросить следующее сообщение и его не оказывается, то вместо wait вызывается nativePollOnce, в который передаётся время, на которое надо уснуть.
Когда мы пытаемся добавить новое сообщение, у нас вместо метода notify вызывается метод nativeWake.
Почему же нельзя воспользоваться обычными wait и notify? Дело в том, что у Android приложений помимо Java слоя есть ещё и прослойка C++, в которой на главном потоке тоже могут происходить различные операции, которые стоит выполнить. Следовательно воспользоваться wait у нас не получится, так как это усыпит главный поток без передачи управления прослойке C++.
В прослойке C++ так же есть свой Looper, но подробнее мы разберём его в следующей статье.
Вызов C++ конечно интересен сам по себе, но есть в MessageQueue что-то, что может пригодиться обычному разработчику? Конечно есть.
IdleHandler
Это особый механизм, который позволяет выполнять какие-либо действия на главном потоке, когда все сообщения из очереди будут выполнены. Он хорошо подходит для действий, которым неважно, когда они будут выполнены - сейчас или через пол секунды. С помощью этого механизма можно избавиться от некоторых фризов, убрав какое-то тяжёлое или не очень действие из основной очереди сообщений.
Например, в приложении VK отметка о том, что сообщение прочли, выставляется именно таким образом, а в ЦИАН IdleHadler используется для тяжёлых действий при работе с картой.
Давайте посмотрим на реализацию этого механизма. По своей сути IdleHandler - это обычный интерфейс с одним единственным методом - queueIdle. В нём и будет содержаться действие, которое мы планируем выполнить.
1
2
3
public static interface IdleHandler {
boolean queueIdle();
}
Как можно заметить, этот метод возвращает boolean. Если вернуть false, то наше действие больше не повторится, если же вернуть true - то наше действие выполнится ещё раз. Поэтому лучше лишний раз не ставить true, дабы избежать ситуаций, когда у нас появляется бесконечно повторяющееся действие на главном потоке.
В классе MessageQueue в поле mIdleHandlers находится список ещё не выполненных IdleHandler, а также есть метод для добавления нового IdleHandler - addIdleHandler.
1
2
3
4
5
6
7
8
9
10
private final ArrayList<IdleHandler> mIdleHandlers = new ArrayList<IdleHandler>();
public void addIdleHandler(@NonNull IdleHandler handler) {
if (handler == null) {
throw new NullPointerException("Can't add a null IdleHandler");
}
synchronized (this) {
mIdleHandlers.add(handler);
}
}
Единственной особенностью addIdleHandler является синхронизация.
Теперь надо как-то узнать, что основная очередь сообщений опустела и настало время выполнения IdleHandler’ов. Для этого в методе next, после того как станет понятно, что доступных для выполнения сообщений в основной очереди нет, выполнится следующий код:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
Message next() {
int pendingIdleHandlerCount = -1;
..................
if (pendingIdleHandlerCount < 0
&& (mMessages == null || now < mMessages.when)) {
pendingIdleHandlerCount = mIdleHandlers.size();
}
if (pendingIdleHandlerCount <= 0) {
mBlocked = true;
continue;
}
..................
}
По сути произойдёт проверка, что в ходе выполнения метода next, IdleHandler’ы ещё не запускались, а также что сообщений в очереди, которые нужно обработать прямо сейчас, уже нет. Если это так, то начнётся обработка IdleHandler, иначе просто будет обработано следующее сообщение.
Настало время выполнить IdleHandler.
1
2
3
4
5
6
7
8
9
10
private IdleHandler[] mPendingIdleHandlers;
Message next() {
..................
if (mPendingIdleHandlers == null) {
mPendingIdleHandlers = new IdleHandler[Math.max(pendingIdleHandlerCount, 4)];
}
mPendingIdleHandlers = mIdleHandlers.toArray(mPendingIdleHandlers);
..................
}
Для этого значения из mIdleHandlers копируются в отдельный массив mPendingIdleHandlers. Отдельный массив нужен, чтобы избежать проблем с многопоточностью.
Само же выполнение происходит достаточно стандартно. В цикле мы проходим по нашим IdleHandler и последовательно выполняем каждый из них.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
private IdleHandler[] mPendingIdleHandlers;
Message next() {
..................
for (int i = 0; i < pendingIdleHandlerCount; i++) {
final IdleHandler idler = mPendingIdleHandlers[i];
mPendingIdleHandlers[i] = null;
boolean keep = false;
try {
keep = idler.queueIdle();
} catch (Throwable t) {
Log.wtf(TAG, "IdleHandler threw exception", t);
}
if (!keep) {
synchronized (this) {
mIdleHandlers.remove(idler);
}
}
}
pendingIdleHandlerCount = 0;
}
При этом выполнение обёрнуто в try-catch. После выполнения, в зависимости от результата метода queueIdle, IdleHandler удалится из общего списка на выполнение. Если во время выполнения IdleHandler бросит исключение, то он так же удалится из списка на выполнение.
От чего-то полезного перейдём к тому, чем вы по идее никогда не должны пользоваться, ну разве что очень редко.
syncBarrier
syncBarrier нужен для того, чтобы остановить выполнение очереди сообщений по какой-либо причине.
К сожалению (или к счастью) методы работы с syncBarrier помечены аннотацией Hide, а значит мы не сможем вызвать их из своего кода честными методами.
Основной способ использования этого механизма появился в Android 5. В нём появился выделенный поток для рендеринга (до этого рендеринг происходил на главном потоке). Из-за этого пришлось придумывать как останавливать обработку главного потока, а конкретно его задач, связанных с интерфейсом, пока поток рендеринга считывал дерево View.
Работает этот механизм очень просто. Для того чтобы исполнение очереди сообщений приостановилось, в очередь сообщений добавляется особо промаркированное сообщение.
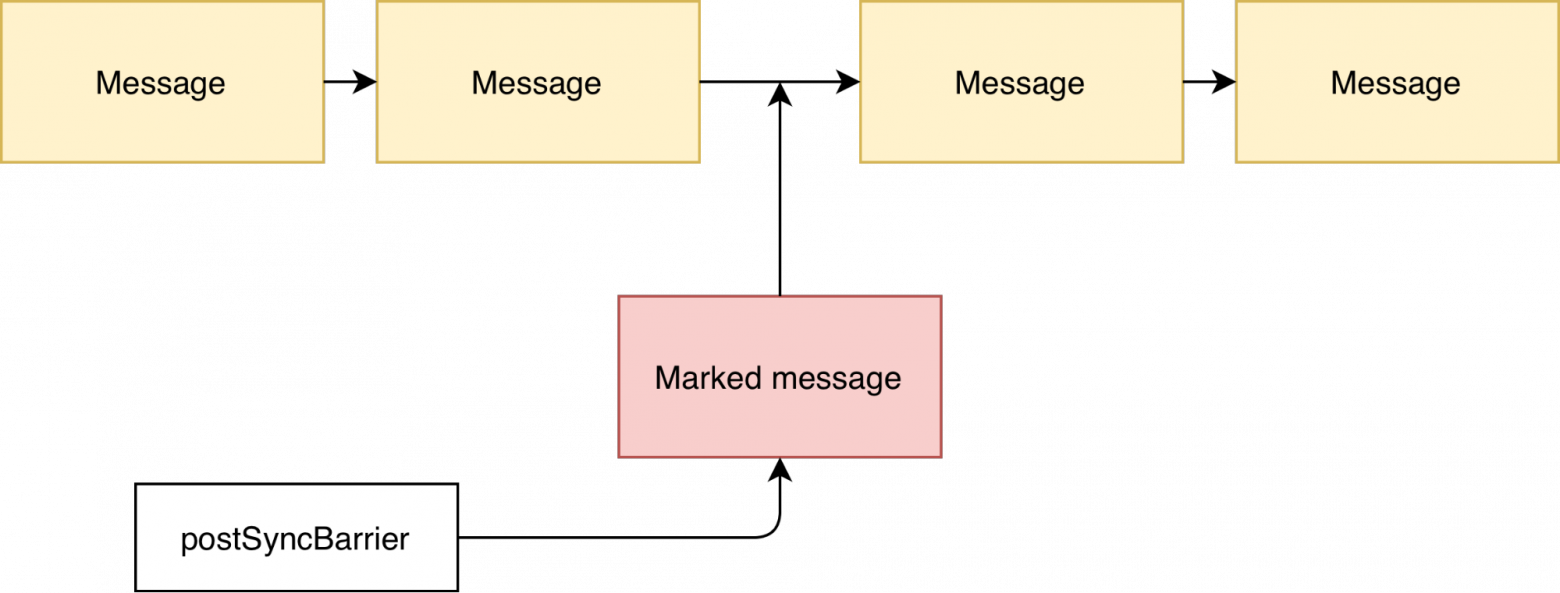
Далее, когда при выполнении метода MessageQueue next оно окажется следующим, то очередь сообщений остановится вместо того чтобы выполнять сообщения.
Затем, когда нужно восстановить обработку очереди сообщений, промаркированное сообщение удаляется и очередь продолжает работать как ни в чём не бывало.
Но ведь не всё задачи главного потока связаны с отрисовкой View. Зачем останавливать все сообщения? Разработчики Android SDK подумали так же. Вы можете пометить ваше сообщение как асинхронное, с помощью метода Message.setAsynchronous(true). На такие сообщения syncBarrier не распространяется и они продолжат выполняться в обычном режиме.
Message
Важное примечание. Класс Message и Handler мы будем рассматривать только в контексте главного цикла. Другие их особенности, связанные с возможностью передачи сообщений между потоками и между разными узлами приложения - сейчас опустим.
Pool, obtain, recycle
У Message имеется private конструктор. Для чего это сделано? Так как, за время работы процесса в нём генерируется и пересылается огромное количество сообщений, то каждый раз создавать новый объект Message будет весьма затратно. Даже такая простая вещь как создание объекта при большом количестве вызовов может иметь значение. Поэтому используется особый pool сообщений. В него будут складываться уже ставшие ненужными объекты Message и, когда нам понадобится новое сообщение, мы вместо создания нового объекта просто будем переиспользовать старый ненужный объект.
Так же, как и в случае с очередью сообщений, pool представляет из себя односвязный список, ссылка на начало которого хранится в поле sPool. Отдельным полем sPoolSize хранится размер этого списка, он нам понадобится, чтобы наш pool не слишком разрастался и мы могли контролировать его размер.
1
2
3
private static Message sPool;
private static int sPoolSize = 0;
public static final Object sPoolSync = new Object();
Так как конструктор приватный, то новое сообщение создаётся через метод obtain. Рассмотрим его подробнее:
1
2
3
4
5
6
7
8
9
10
11
12
13
public static Message obtain() {
synchronized (sPoolSync) {
if (sPool != null) {
Message m = sPool;
sPool = m.next;
m.next = null;
m.flags = 0;
sPoolSize--;
return m;
}
}
return new Message();
}
Первое что нас ждёт - блок синхронизации, внутри него мы смотрим - есть ли у нас сообщения в sPool. Если есть, то забираем первое сообщение из pool и возвращаем его, при этом не забывая поменять ссылку на начало списка и уменьшить значение sPoolSize.
Если же в sPool сообщений нет, то создаём новое сообщение через приватный конструктор. Но как объекты попадают в sPool? Для этого, после того как MessageQueue выполняет действие сообщения, оно вызывает у него метод recycle.
1
2
3
4
5
6
7
8
9
10
public void recycle() {
if (isInUse()) {
if (gCheckRecycle) {
throw new IllegalStateException("This message cannot be recycled because it "
+ "is still in use.");
}
return;
}
recycleUnchecked();
}
Внутри этого метода сначала проверяется - используется ли сейчас сообщение, если да, то бросается исключение, ведь в sPool должны попадать уже ненужные сообщения. Иначе вызывается приватный метод recycleUnchecked.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
void recycleUnchecked() {
flags = FLAG_IN_USE;
what = 0;
arg1 = 0;
arg2 = 0;
obj = null;
replyTo = null;
sendingUid = UID_NONE;
workSourceUid = UID_NONE;
when = 0;
target = null;
callback = null;
data = null;
synchronized (sPoolSync) {
if (sPoolSize < MAX_POOL_SIZE) {
next = sPool;
sPool = this;
sPoolSize++;
}
}
}
Внутри recycleUnchecked во все поля сообщения выставляются значения по умолчанию, а затем если наш pool ещё не заполнен, то в него добавляется наше сообщение, при этом значение sPoolSize увеличивается.
Handler
Зачем он нужен
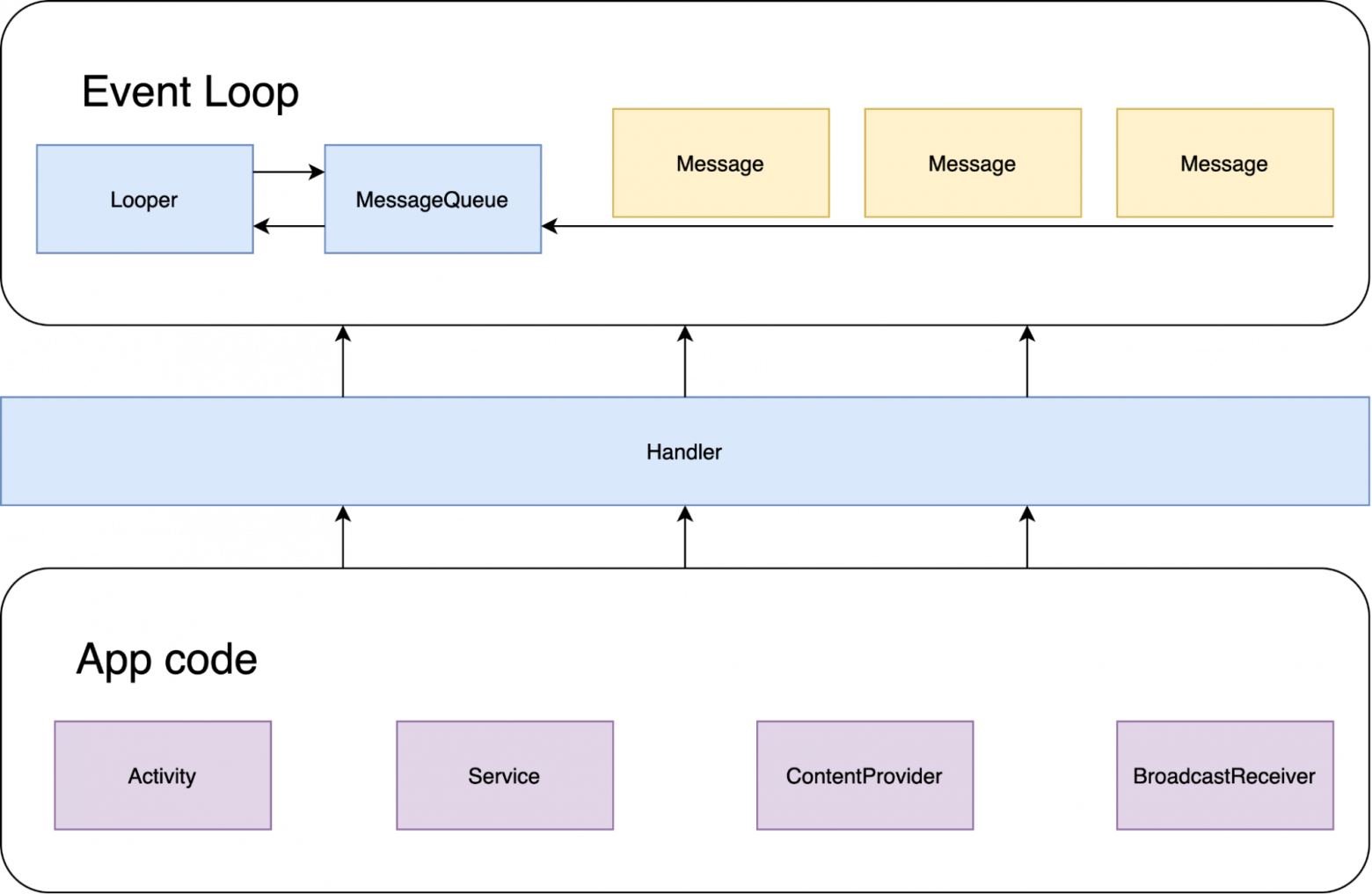
Помимо Looper, Message и MessageQueue в главном цикле Android SDK присутствует ещё один класс - Handler. Для чего же он нужен? Дело в том, что что с точки зрения безопасности и стабильности кода давать программистам прямой доступ к очереди сообщений может быть опасно. Помимо того, что кто-то может напакостить, поменяв очередь, так ещё и такие изменения будет очень сложно отследить. Для решения этой проблемы и нужен Handler, он является фасадом для логики работы с очередью сообщений.
Если мы захотим из кода приложения добавить новое сообщение в очередь, то мы должны делать это через Handler, напрямую это сделать никак не получится, так как большинство методов MessageQueue имеют видимость package-local, а не public.
post и postDelayed
Итак, мы захотели добавить новое сообщение в очередь. Как нам это сделать? Для добавления нового сообщения в очередь у Handler есть методы post и postDelayed. Эти методы есть не только у Handler, но и например у view: post, postDelayed, есть аналог и у Activity: runOnUiThread, но все они так или иначе в итоге сводятся к вызову Handler.
Метод post просто добавляет новое сообщение в конец очереди.
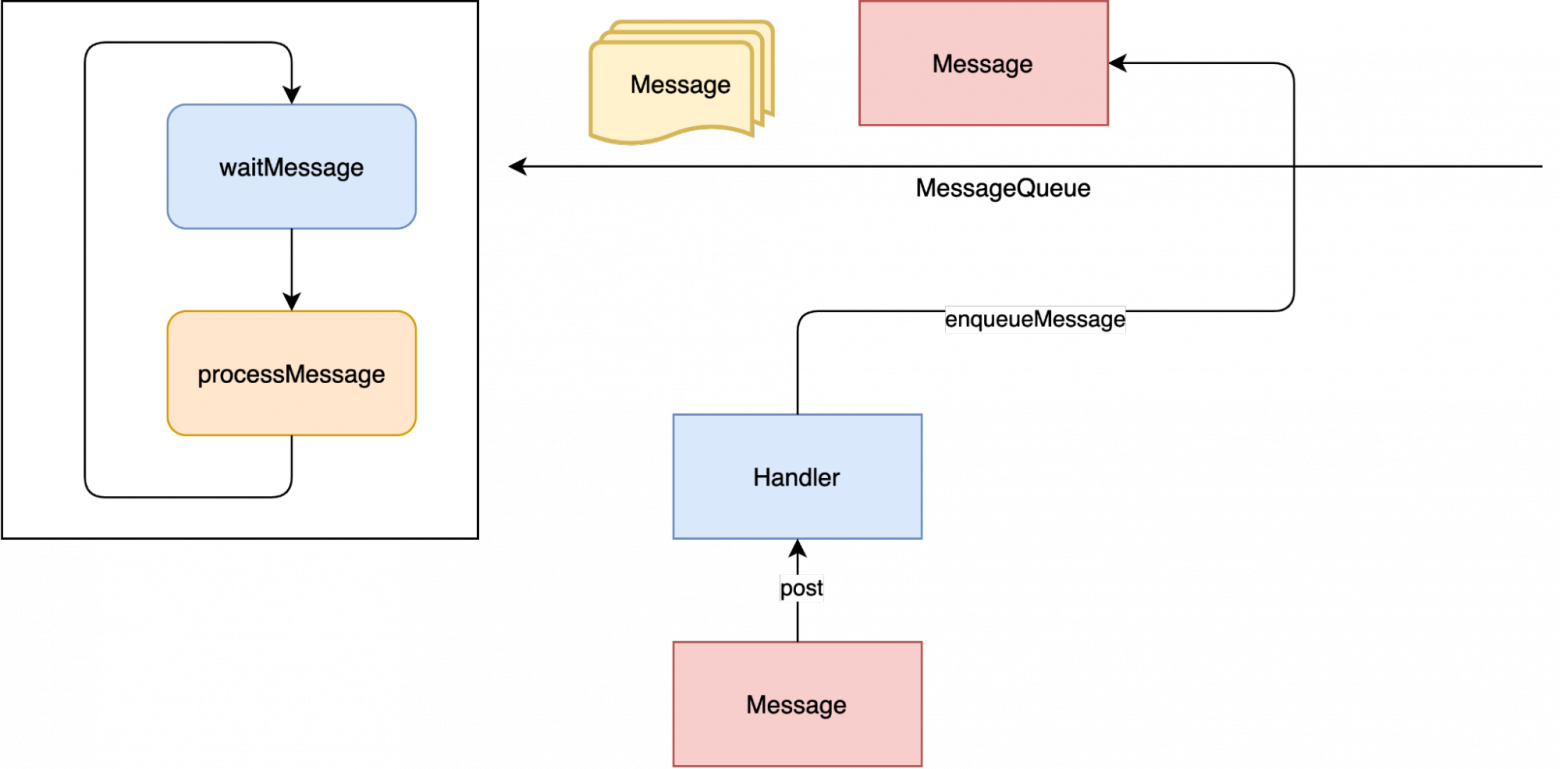
Метод postDelayed добавляет отложенное сообщение, которое выполнится через определенный промежуток времени. Для этого в поле when класса Message записывается время с момента старта JVM + время через которое надо выполнить сообщение, таким образом MessageQueue понимает когда надо выполнить сообщение.
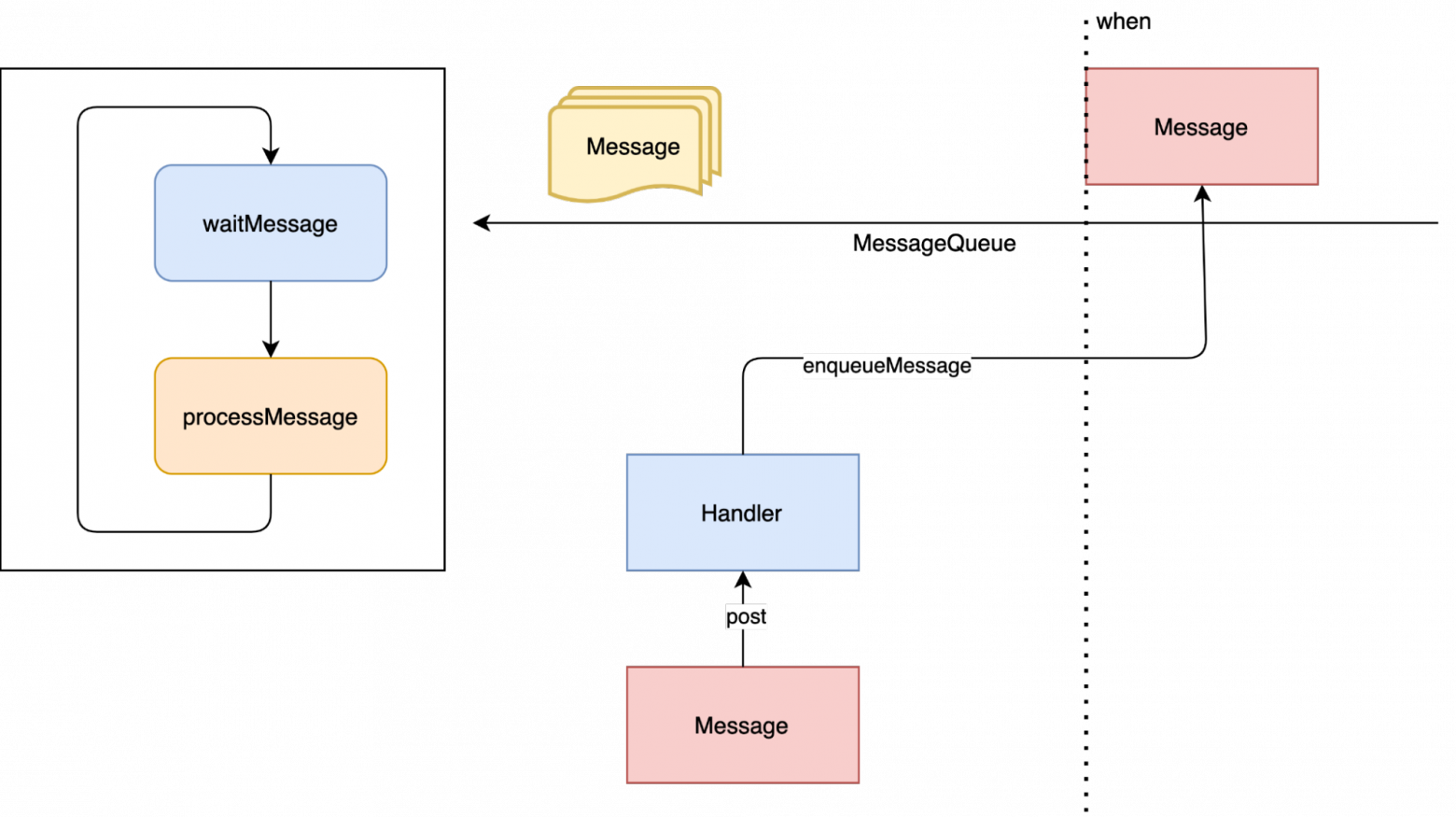
Стоит заметить, что с postDelayed стоит быть аккуратными если вы используете их в объектах с коротким жизненным циклом. Иначе может сложиться ситуация, когда ваш объект уже готов быть собран сборщиком мусора, но сообщение, которое он отправил, ещё не успело выполниться. В случае с post беда не велика и я бы даже назвал это микроутечкой памяти, но в случае с postDelayed это уже может быть скорее миниутечка, ведь объект утечёт на тот период времени, что вы указали.
На мой взгляд, это пожалуй всё самое интересное из Android SDK, связанное с Looper, MessageQueue и Message. Поэтому можно сказать, что как главный цикл работает в Android SDK и какие особенности имеет мы разобрались. По крайней мере на слое Java, но есть же ещё и упомянутый C++ слой. Да и не секрет, что Android приложения пишутся не только с помощью Java Android SDK, есть Flutter, React Native, Chrome и игры.
Другие главные циклы
В этой части мы посмотрим на особенности Looper в C++, поверхностно пробежимся по Flutter, Chrome и React Native. А ещё есть игры — в них вообще всё с ног на голову.
Тут мы начинаем заходить на окраину территории моих знаний, поэтому если где-то будут неточности, то обязательно поправляйте меня в комментариях. Также из-за этого в статье будет много ссылок, чтобы было что почитать на досуге.
Looper в C++ слое
Общая логика
В предыдущей части я упомянул, что Looper из Java вызывает Looper из C++. Как можно догадаться, в слое C++ есть свой Looper, который отвечает за сам цикл и его работу, своя очередь сообщений и свой Message. Далее в рассуждениях я буду отталкиваться от того, что вы прочли предыдущие части статьи и/или понимаете общую логику работы главного цикла и его особенности в Java слое Android SDK.
В итоге у нас есть два Looper, а значит, нужно как-то передавать управление C++ слою. Для этого в Java слое вызывается метод nativePollOnce. Каждый раз когда в MessageQueue мы пытаемся найти следующее сообщение, сначала вызывается nativePollOnce. В этот момент наступает очередь Looper из C++ обрабатывать сообщения, и он вернёт управление в Java слой лишь тогда, когда он закончит обрабатывать все свои текущие сообщения. Важно понимать, что оба этих Looper работают в одном потоке — MainThread, то есть у нас имеется две очереди основных событий на один поток. Следовательно, если «заспамить» очередь из C++, то очередь из Java вообще не будет продвигаться. Получается следующая схема:
Интересно, что с точки зрения кода Looper из C++ сочетает в себе и логику Looper и логику MessageQueue. Да и в целом написан не так аккуратно, как его собрат из Java слоя. При желании можете удостовериться в этом сами, посмотрев его исходный код с заголовочным файлом. По этой причине, код я прикладывать особо не буду, но всё же рассмотрим избранные куски.
Для начала начнём с самого сообщения — класса Message. Оно здесь сделано настолько просто, насколько это вообще было возможно. По сути у нас есть только одна переменная what и два конструктора.
1
2
3
4
5
struct Message {
Message() : what(0) { }
Message(int w) : what(w) { }
int what;
};
А как же тогда указать в сообщении, что оно должно делать? Для этого в переменную what надо записать идентификатор действия, которое мы хотим выполнить. Затем обработчик считает этот идентификатор и выполнит соответствующее действие. В качестве обработчика выступают наследники MessageHandler.
1
2
3
4
5
6
class MessageHandler : public virtual RefBase {
protected:
virtual ~MessageHandler();
public:
virtual void handleMessage(const Message& message) = 0;
};
У MessageHandler есть всего один виртуальный (считай абстрактный) метод, который мы и должны переопределить. Внутри него мы можем считать идентификатор и выполнить действие, которое к нему предписано. В целом если делать по отдельному MessageHandler на каждый Message, то всеми премудростями с идентификатором можно и не заниматься. Есть сообщение и есть его обработчик, который всегда выполняет одно и тоже действие.
Но как нам теперь связать сообщение с его обработчиком? Для этого существует MessageEnvelope. В нём и находятся:
- экземпляр
Messageс которым познакомились выше; - StrongPointer на
MessageHandler, являющийся указателем с встроенным счетчиком ссылок, чтобы мы могли, без лишних проблем, переиспользовать один экземплярMessageHandlerдля нескольких сообщений; uptimeдля хранения времени со старта процесса. Она несёт в себе такой же смысл как иwhenвMessageиз Java, то есть это время в которое надо выполнить сообщение. Очень полезно для отложенных операций.
1
2
3
4
5
6
7
8
struct MessageEnvelope {
MessageEnvelope() : uptime(0) { }
MessageEnvelope(nsecs_t u, sp<MessageHandler> h, const Message& m)
: uptime(u), handler(std::move(h)), message(m) {}
nsecs_t uptime;
sp<MessageHandler> handler;
Message message;
};
По сути, создав объект MessageEnvelope, мы свяжем наше сообщение с его обработчиком. Такой объект уже можно, без зазрения совести, класть в очередь сообщений. Кстати о ней.
Она представлена обычным классом Vector, который по сути является улучшенным одномерным массивом. Как я упоминал выше - хранится эта очередь в самом Looper в переменной mMessageEnvelopes.
1
Vector<MessageEnvelope> mMessageEnvelopes;
В основной логике Looper из C++ похож на своего собрата из Java слоя, но у него есть один нюанс, который мы ещё не рассмотрели. Если Looper из Java вместо ожидания передает управление в Looper из C++, то что же делает последний, когда сообщения в очереди закончились и надо действительно ждать? Передавать управление более нижнему слою уже нельзя, мы на самом дне. Надо действительно ждать.
Ожидание
Для начала давайте посмотрим чуть подробнее на wait и notify из Java. Каждый объект в Java имеет свой монитор. При вызове wait у монитора произойдет перемещение текущего потока в wait set монитора. Пока поток находится в wait set он «спит». При вызове notify или notifyAll пробуждается один или все потоки, которые сейчас находятся в wait set монитора.
В С++ похожее поведение реализуют condition_variable, но в Looper используется другой подход - связка epoll + eventfd. В отличии от wait-notify/condition_variable, которые предоставляют синхронизацию только внутри процесса, epoll + eventfd предоставляет синхронизацию как внутри процесса, так и между процессами. Взглянем на этот подход подробнее. Начнем с eventfd.
eventfd
Прежде чем разбираться с eventfd, нужно сначала разобраться с тем, что такое файловый дескриптор, так как логика eventfd основана на нём.
Мне наиболее простым и понятным кажется определение файлового дескриптора как - уникальный идентификатор для ресурса ввода-вывода. Им может быть файл, каталог, сокет, stdin, stdout и т.д. Сам файловый дескриптор управляется на уровне операционной системы. Когда вы хотите открыть файл или сокет, или что-то еще, это делает ядро. Оно знает много чего ещё про открытый файл, но отдаёт только этот идентификатор (который, кстати, уникален только в рамках одного процесса). Так же нельзя открыть файл с дескрипторами 0, 1 и 2 — при создании процесса ядро автоматически открывает их для ввода, вывода и сообщений об ошибках. Подробнее можно почитать тут.
eventfd - это kernel system call, при вызове возвращающий нам файловый дескриптор, который будет использоваться для уведомления о новых событиях. Может использоваться как внутри приложения, так и для уведомления приложения ядром системы.
Для начала получим наш файловый дескриптор eventfd и поместим его в хранилище в переменной mWakeEventFd:
1
mWakeEventFd.reset(eventfd(0, EFD_NONBLOCK | EFD_CLOEXEC));
Если проводить аналогию с привычным нам подходом wait/notify с монитором, то файловый дескриптор, который нам отдаст eventfd, будет аналогом монитора.
Теперь нужны аналоги для wait и notify. Начнем с wait, в качестве него выступит epoll.
(e)poll
poll - это kernel system call, который позволяет отслеживать файловый дескриптор. epoll - это улучшенная версия poll, которая работает оптимальнее. Что важно, при создании экземпляра epoll нам возвращается файловый дескриптор, указывающий на него, так что в теории мы можем с помощью epoll отслеживать другой экземпляр epoll.
Из этой утилиты нам понадобятся следующий методы - epoll_wait, epoll_ctl и epoll_create1.
Для начала создадим экземпляр epoll, а связанный с ним файловый дескриптор запишем в хранилище в переменной mEpollFd.
1
mEpollFd.reset(epoll_create1(EPOLL_CLOEXEC));
Затем с помощью epoll_ctl мы указываем, что epoll должен отслеживать дескриптор, полученный от eventfd.
1
epoll_ctl(mEpollFd.get(), EPOLL_CTL_ADD, mWakeEventFd.get(), &wakeEvent);
Ну и в конце концов в том месте, где мы будем ждать новых событий, вызовем метод epoll_wait. Он будет ждать появления новых данных об объектах за которыми, с помощью файловых дескрипторов, следит epoll. В итоге он вернёт нам количество событий, произошедших с объектами с момента последнего отслеживания.
1
2
3
4
5
int eventCount = epoll_wait(
mEpollFd.get(),
eventItems,
EPOLL_MAX_EVENTS,
timeoutMillis);
При вызове epoll_wait мы либо сразу получим количество событий с последнего отслеживания, либо, если событий нет, будем их дожидаться. Механизм epoll также поддерживает ожидание по времени - для этого достаточно передать в метод нужное нам время. В нашем случае это делается с помощью переменной timeoutMillis. Это позволяет потоку ждать, пока не поступят новые данные, или не истечет заданное в timeoutMillis время, в зависимости от того, что произойдет раньше. Это нужно для поддержки отложенных сообщений.
То, как Looper начинает ждать мы разобрались. Теперь пора бы перейти к последнему - пробуждению. Тут к счастью всё достаточно просто. Для этого используется write.
write
write - простой метод, который записывает байты в ресурс, связанный с файловым дескриптором. В нашем случае в качестве байтов выступит просто единица формата uint64_t. Нам ведь просто надо уведомить epoll, а не передать какие-либо данные.
1
2
uint64_t inc = 1;
write(mWakeEventFd.get(), &inc, sizeof(uint64_t))
По итогу логика получается следующей:
- создаём объект
eventfdи получаем файловый дескриптор указывающий на него; - создаём экземпляр
epoll; - указываем экземпляру
epollследить за файловым дескриптором, полученным отeventfd; - когда задачи заканчиваются, с помощью
epollначинаем ждать, вызвавepoll_wait; - при появлении нового сообщения пишем в ресурс, привязанный к файловому дескриптору
eventfd, тем самым уведомляяepoll.
Логика не сложная, но достаточно тяжело воспринимаемая из-за непривычных для Android разработчика файловых дескрипторов.
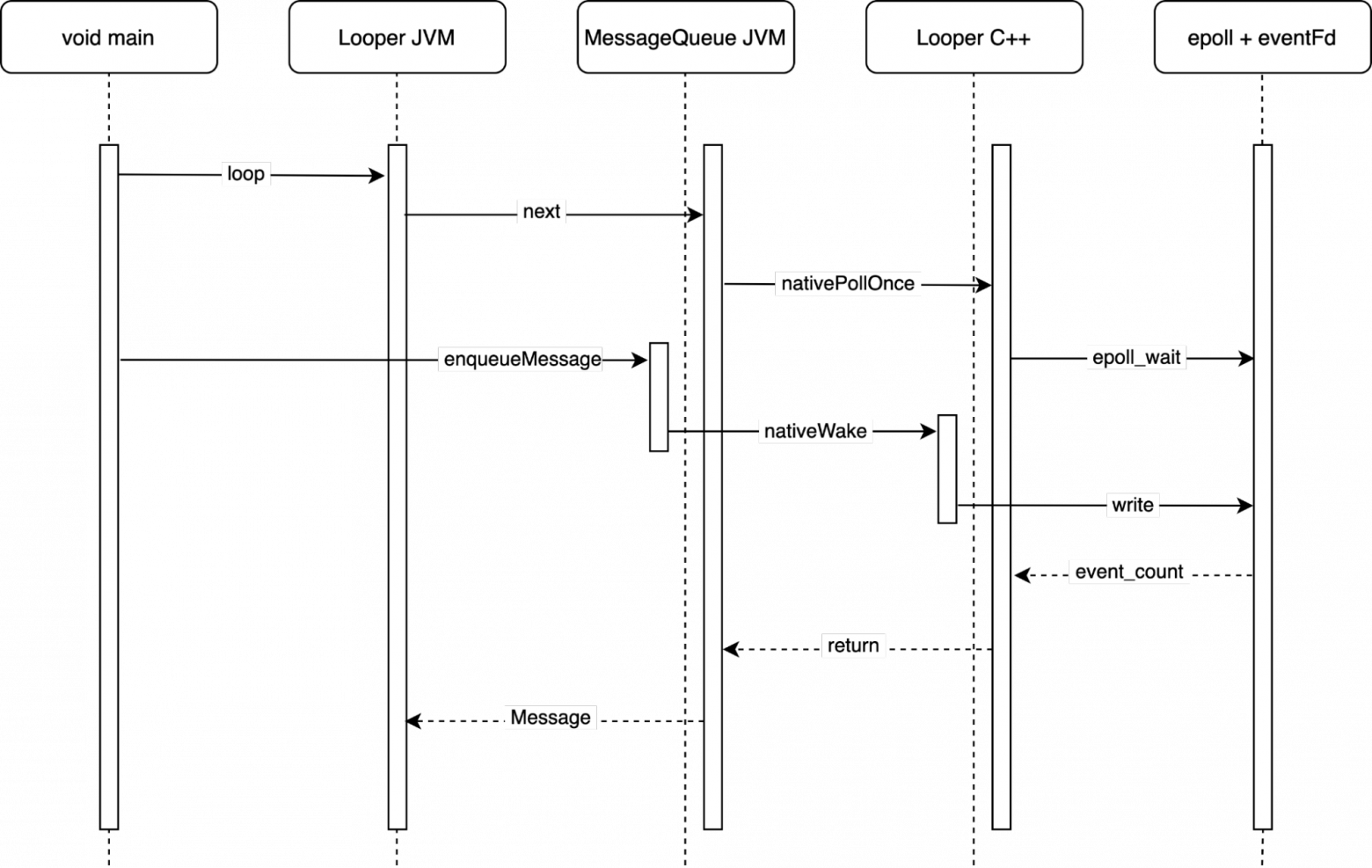
Общий путь ожиданий и пробуждений, включая Java слой, получается довольно длинным:
С Android SDK покончено, давайте перейдём к поверхностному рассмотрению альтернативных фреймворков для разработки под Android. Рассмотрим конечно же не всё. Только то, что является достаточно популярным или обладает своими особенностями.
Flutter
Начнём мы с Flutter. Штука эта мультиплатформенная, так что в зависимости от платформы конечная реализация может быть немного разной. Поэтому рассмотрим всё достаточно абстрактно.
Две очереди
Основной особенностью главного цикла во Flutter является наличие двух очередей: очередь Event и очередь MicroTask.
Первая очередь нам уже привычна и понятна - это очередь основных событий, а вот вторая очередь уже интереснее. Она используется для очень коротких событий, которые желательно выполнить как можно скорее.
С точки зрения кода это выглядит примерно так:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
void loop() {
var isAlive = true;
while (isAlive) {
........................................
while (_microTaskQueue.isNotEmpty) {
final currentMicroTask = _microTaskQueue.first;
currentMicroTask.call();
_microTaskQueue.remove(currentMicroTask);
}
if (_eventQueue.isNotEmpty) {
final currentEvent = _eventQueue.first;
currentEvent.call();
_eventQueue.remove(currentEvent);
}
........................................
}
}
В каждом проходе цикла мы проверяем, есть ли у нас сообщение в очереди событий MicroTask, если там есть сообщение, то оно выполняется и удаляется из очереди. Если нет - то тоже самое происходит с очередью Event. По сути очередь MicroTask - это та же очередь, просто имеющая наивысший приоритет, и пока эта очередь не опустеет, события из очереди Event не будут выполняться.
Isolate
Также во Flutter нет привычной системы потоков, но есть Isolate. Он похож на обычные потоки в других языках, но при этом Isolate не делят память между собой, то есть нельзя по привычной для нас схеме менять одну переменную из двух разных Isolate, а значит и проблем с синхронизацией по большей части нет. Интересующей же нас особенностью является то, что каждый из Isolate имеет свой цикл событий с собственными очередями Event и MicroTask. Общаются же Isolate c помощью сообщений, которые они могут посылать друг другу. Таким образом вообще все действия во Flutter выполняются в циклах событий.
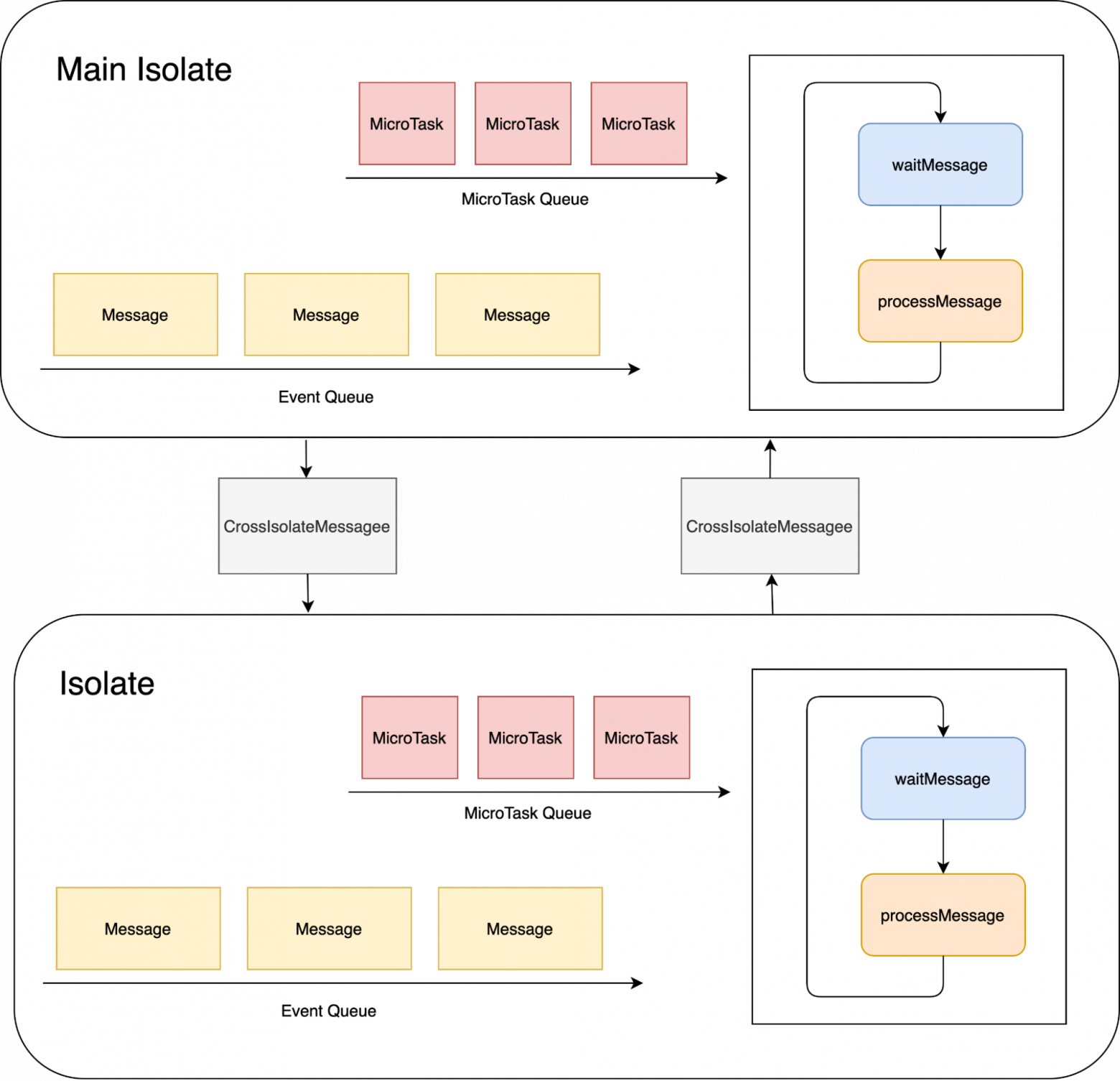
Подробнее про это можно прочитать в этой статье (перевод).
Chrome
Многие фреймворки для кроссплатформенной разработки, например Cordova, используют системный WebView, также не стоит забывать про PWA (хотя, кажется, все уже забыли). Начиная с Android 7, при использовании стандартного WebView под капотом используется Chrome. Следовательно, довольно много Android приложений используют Chrome. Так что стоит присмотреться и к его главному циклу.
Он основан на open-source библиотеке libevent. Эта кроссплатформенная библиотека, специально созданная для реализации циклов событий как UI, так и серверных приложений. Она сразу предоставляет все самые необходимые вещи как: отложенные сообщения, множественные очереди, приоритеты и прочие вещи которые могут понадобиться при работе с циклами событий.
(Кстати, в Android SDK эта библиотека тоже есть, но по какой-то причине для главного цикла не используется, правда и добавили её туда только в 2015 году.)
В зависимости от платформы libevent использует разные способы ожидания/пробуждения. Конкретно в Android используется старый добрый epoll + eventfd. В других платформах реализация может отличаться.
Поверх этой библиотеки написана обёртка. В целом логика похожа на цикл Flutter (что не удивительно, учитывая “корни” языка Dart) - отдельная очередь Task и отдельная очередь Microtask. Но есть особенность, которая сильно выделяется - часть задач, связанных с рендерингом, находится в отдельной очереди.
Подробнее о главном цикле Chrome можно прочитать в этой статье. Я же просто приведу диаграмму оттуда.
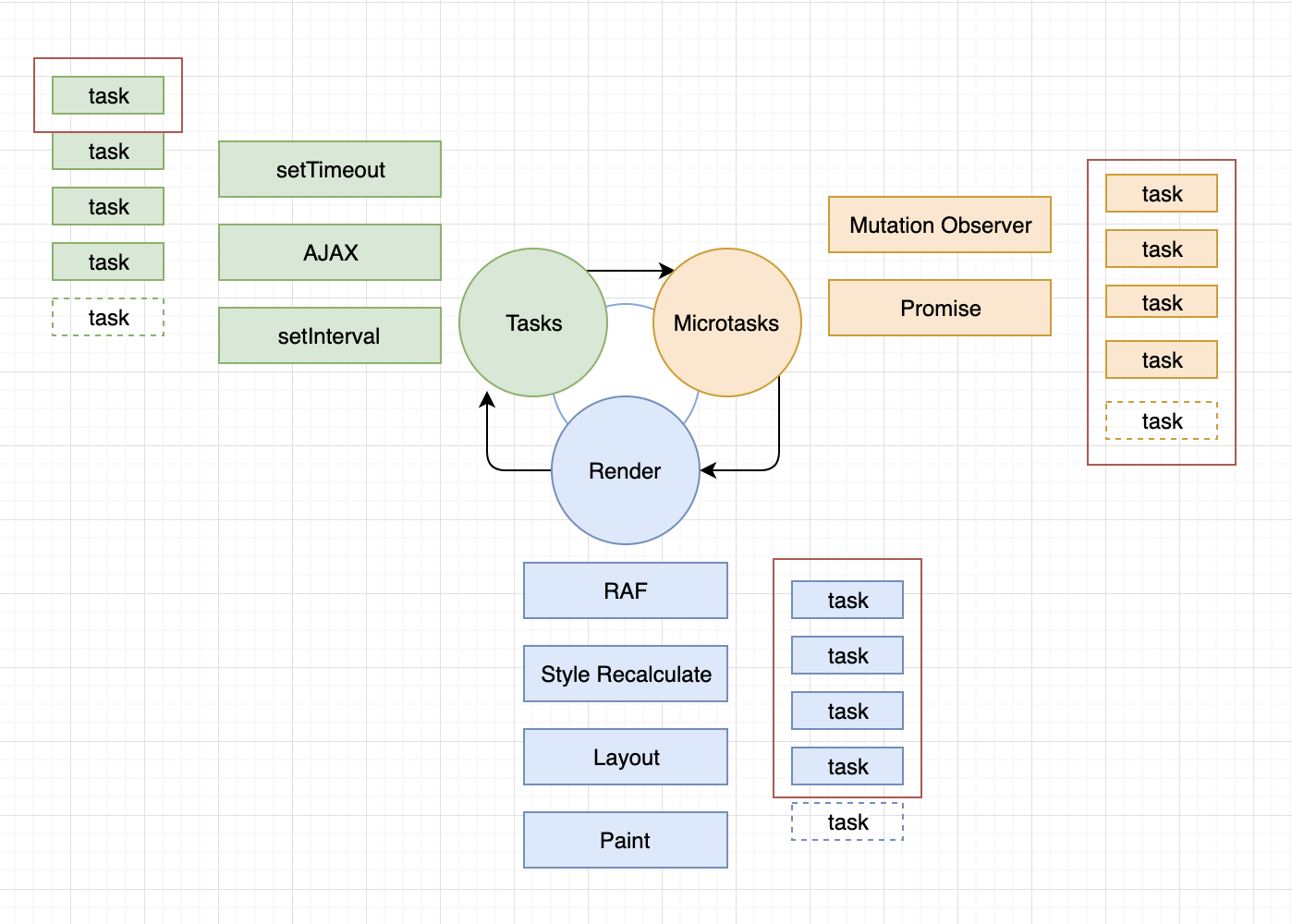
То есть мы уже имеем целых три очереди на один цикл событий.
Если открыть инструменты разработчика в Chrome, то мы можем увидеть прекрасную картину работы главного (и не только) потока.
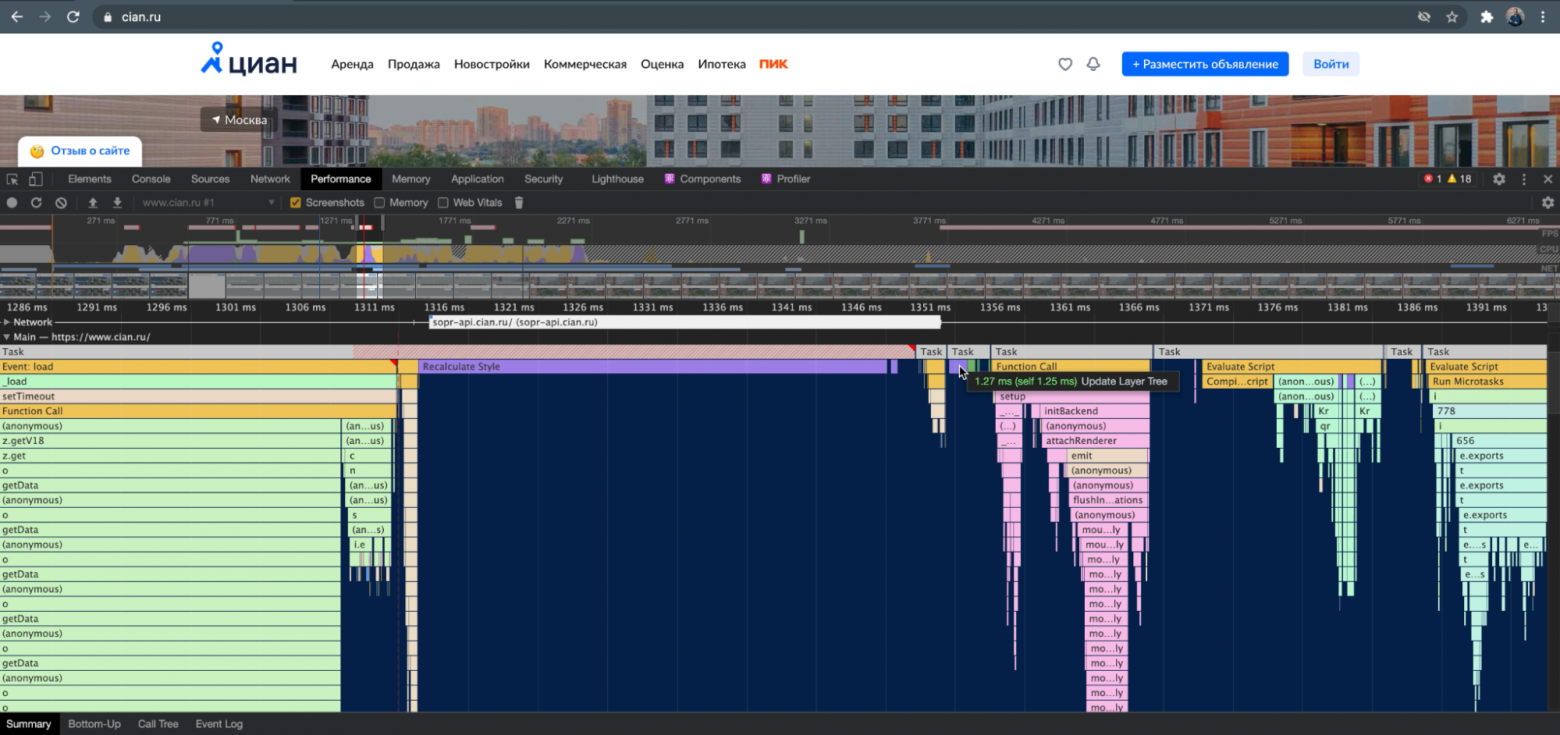
Сообщения из очереди Render здесь обозначены сиреневым цветом.
Если вас заинтересовала тема рендеринга, то вот статья про рендеринг во Flutter, в которой есть сравнение с Chromium и Android SDK.
React Native
Особенности главного цикла в React Native уходят корнями в логику потоков. Давайте взглянем на потоки main и JsThread:
main- старый, добрый, привычный. Именно в нём приложение начинает свою работу. Сначала он загружает пакеты JS, и после этого вся работа с JS ведётся в отдельном потоке. Main продолжает разве что просто обновлять View.JsThread- поток, в котором выполняется весь Javascript. В нём по сути происходит всё самое важное, что может случиться в React Native приложении. Обновления нативных view группируются, и отправляются в главный поток каждый оборот главного цикла.
В итоге получается, что MainThread здесь используется только для отрисовки и чтобы загрузить JS. Вся логика происходит в JsThread, у которого есть собственный цикл. Так что на вопрос “Кто тут главный?” в рамках ReactNative ответить сложнее.
KMM
Сказать тут особо нечего, так как код Kotlin Native по сути вызывается из Android SDK, то логично, что главный цикл используется оттуда же. Тем не менее в KMM есть собственный EventLoop для корутин, но главным циклом он, увы, не является.
Игры
В играх главный цикл отличается больше всего. Основной его особенностью является то, что он работает всегда, загружая вашу систему насколько это позволяет движок. Ведь листики на деревьях должны двигаться в соответствии с ветром, даже если игрок никак в данный момент не взаимодействует с игрой.
Ну тут, хотя бы не надо так заморачиваться с ожиданием и пробуждением цикла. Всё должно быть проще, правда? Нет, не правда, на деле тут всё даже сложнее.
Итак, задача следующая - за один проход цикла нам надо:
- Считать ввод пользователя с экрана, геймпада или клавиатуры. Для этого сделаем метод
processInput. - Просчитать физику, геометрию, поворот камеры, искусственный интеллект и пр. То есть в итоге мы должны получить позиции всех точек для полигонов. Пусть это делается в методе
updatePhysics. - На основе точек отрисовать наши полигоны, наложить на них текстуры, шейдеры, отражения и пр., чтобы в конце выполнить растеризацию. Пусть это делается в методе
updateRender.
В нашем примере processInput, updatePhysics, updateRender - это просто методы, но в реальности используются привычные нам схемы с очередями и сообщениями. Так как мы уже достаточно разобрались как работают очереди, то в дальнейшем мы будем ими пренебрегать.
Подход в лобовую
Первое что приходит в голову - просто взять и запустить наши методы в бесконечном цикле, выглядеть это будет примерно следующим образом:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
class GameLooper {
private var isRunning = true
fun loop() {
while (isRunning) {
processInput()
updatePhysics()
updateRender()
}
}
private fun processInput() {
..................
}
private fun updatePhysics() {
..................
}
private fun updateRender() {
..................
}
}
Ииииии… Это работает, но плохо. Главная проблема такого цикла в том, что он не привязан ко времени. По сути, чем мощнее железо телефона, тем быстрее будет выполняться наша игра, но если железо медленное, то игра будет идти наоборот очень медленно.
Чтобы понять почему это происходит давайте представим, что в нашей игре есть персонаж, и пока нажата кнопка «вперёд», он идет вперед (да да!!!). Делается это с помощью метода walk, который двигает нашего персонажа ровно на метр вперед. Обработка физики для этого метода занимает на слабом железе — допустим 1 секунду, а на мощном железе — 0,5 секунды.
Получается, что если пользователь жмёт на кнопку 3 секунды, то на медленном железе метод успеет выполниться 3 раза, а на мощном — 6. Соответственно, на мощном железе персонаж пройдет в два раза большее расстояние.
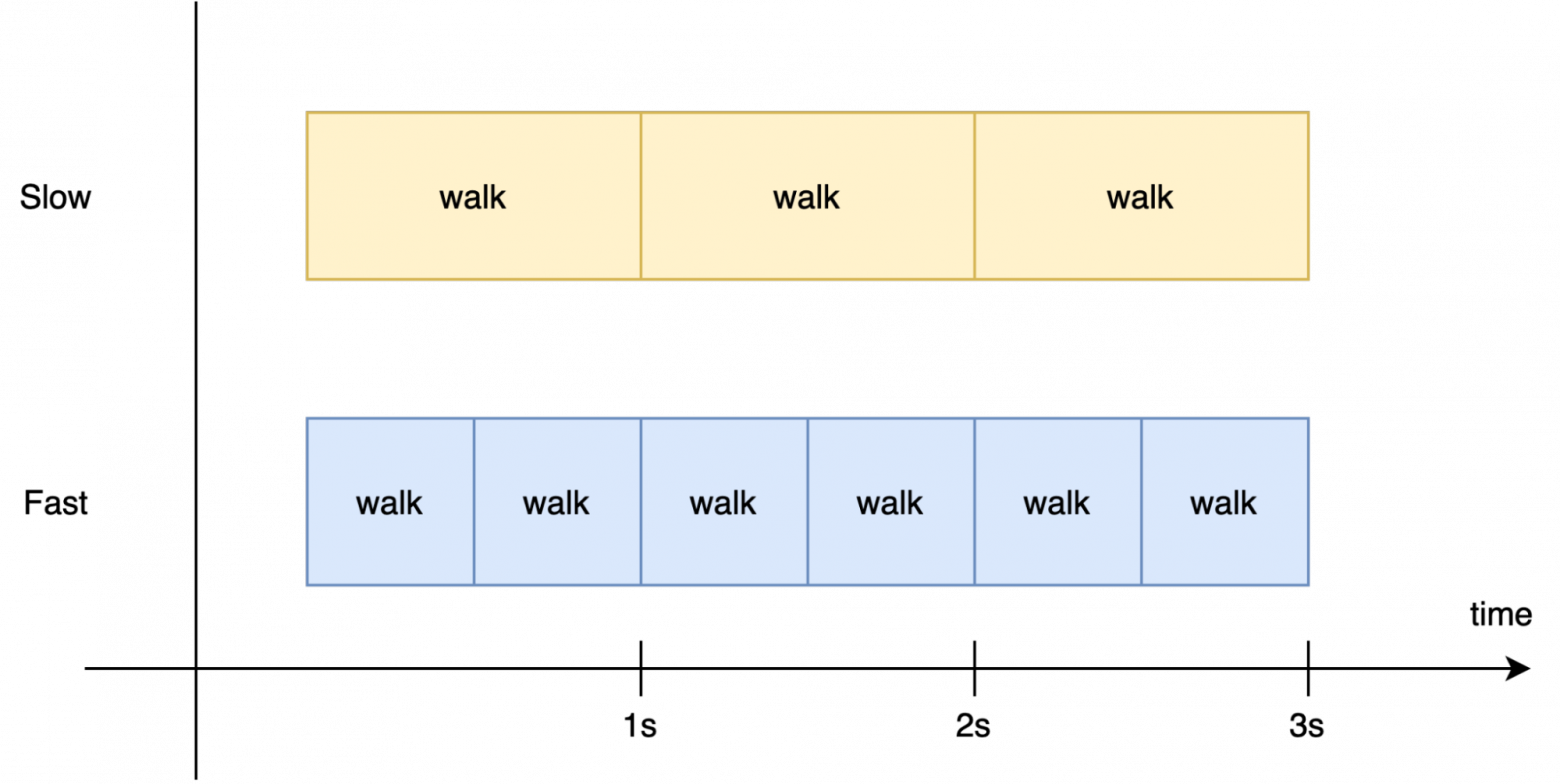
В реальной же игре вообще все объекты будут двигаться в два раза быстрее. Согласитесь — такой геймплей нам не нужен.
Как же от этого избавиться?
Постоянное количество кадров
Проще всего взять и сделать количество кадров константным. Для этого выберем константу например — 25 кадров в секунду. Если же наша игра работает быстрее, чем 25 кадров в секунду, то вызывается старый добрый метод Thread.sleep, и наш цикл уснёт до тех пор, пока не придёт время нового кадра.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
private const val FRAMES_PER_SECOND = 25
private const val SKIP_TICKS = 1000 / FRAMES_PER_SECOND
class GameLooper {
private var isRunning = true
fun loop() {
var nextGameTick = SystemClock.uptimeMillis()
while (isRunning) {
processInput()
updatePhysics()
updateRender()
nextGameTick += SKIP_TICKS
val sleepTime = nextGameTick - SystemClock.uptimeMillis()
if (sleepTime > 0) {
Thread.sleep(sleepTime)
}
}
}
}
Такое решение лучше предыдущего, на среднем и мощном железе оно будет работать с одинаковой скоростью. И на этом плюсы этого решения заканчиваются.
Проблема с тем, что на слабом железе наша игра работает медленно, никуда не ушла. Получается эдакое лагающее slo-mo, такое можно заметить например в Dark Souls.
С мощным железом всё тоже не очень хорошо. По факту, оно простаивает большую часть времени, просто находясь в ожидании времени наступления следующего кадра. Хотя и у этого решения есть плюсы - меньше расходуется батарея на телефоне. Но всё же, чем мощнее железо, тем больше оно спит.
Это не очень хорошо, ведь пользователь покупал мощный телефон со 120 Гц экраном не для того, чтобы быть ограниченным 25 кадрами. Поэтому займемся проблемами скорости игры.
Реальное время
Если задуматься, то станет очевидно, что такие вещи, как звуки и анимации, завязаны на реальном времени. Звук должен проигрываться определённое количество времени независимо от мощности железа. Почему бы и в случае с графикой тогда не смотреть на реальное время и уже подстраиваться под него.
Правда придётся переписать все расчёты физики, чтобы они учитывали время, так что хорошо, что наш проект гипотетический. Мы просто будем прокидывать время, которое прошло с предыдущего кадра, прямо в метод updatePhysics и уже в самих расчетах отталкиваться от количества времени которое прошло.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class GameLooper {
private var isRunning = true
fun loop() {
var currentFrameTick = SystemClock.uptimeMillis()
while (isRunning) {
val prevFrameTick = currentFrameTick
currentFrameTick = SystemClock.uptimeMillis()
processInput()
updatePhysics(currentFrameTick - prevFrameTick)
updateRender()
}
}
}
В итоге наша игра идёт с одинаковой скоростью независимо от мощности железа (не считая совсем уж низкий FPS). Первая победа!
Этот вариант кажется практически идеальным, но у него есть и минусы.
На слабом железе всё достаточно хорошо. Конечно если FPS будет совсем уж низким - 10-15 кадров в секунду, то управлять игрой станет практически невозможно, так как в отличии от предыдущих вариантов игра не замедляется давая игроку возможность сориентироваться. Но откровенно говоря играть на таком FPS практически невозможно при любом цикле событий.
На мощном железе может происходить магия. В чём она заключается? Ну, возможно, некоторые объекты будут летать (а не должны), что-то двигаться слишком быстро, а что-то слишком медленно. В чем же причина такой магии? В дробных числах.
Дробные числа, вроде Float или Double, имеют фиксированное количество цифр после запятой и вообще не являются идеально точными. Например, 0.1 может оказаться как 0,10000000000000001, так и 0,99999999999999976. Для примера давайте возьмём простой код:
1
println("%f".format(1f * 1_000_000_000_000))
Мы просто взяли единицу формата Float и умножили на очень большое число. В итоге нам выведется 999999995904.000000. Погрешность стала уже достаточно большой.
Обычно это не вызывает проблем. Но допустим у нас есть гусеница, которая проползает 0.0001 метра в секунду. При 30 кадров в секунду мы должны будем подвинуть гусеницу на 1/30 от этого расстояния - 0,0000033, при 120 уже на 1/120 - 0,000000833. Чем выше FPS тем меньшими дробями нам приходится оперировать и тем сильнее может сказываться погрешность. Очень наглядным примером является Skyrim, который при высокой частоте кадров начинает запускать телеги в воздух.
Не факт, что конкретно в вашей игре погрешность Float на что-то повлияет, но это одна из тех вещей, которая может с вами случиться. Избавиться от этого можно просто стараясь не использовать очень малые дроби. Но, так как у нас тут статья про главный цикл, давайте попробуем исправить это за счёт изменения цикла.
Да и в целом, физические движки любят постоянство.
Постоянство Шрёдингера
Раз проблема с погрешностью Float проявляет себя в первую очередь в расчётах физики, то давайте зададим ей постоянную частоту обновления, а отрисовка пусть происходит так часто, как это вообще возможно. Получится одновременно и постоянная частота и не постоянная.
Условимся, что наша физика должна рассчитываться 50 раз в секунду. Путём несложных вычислений мы понимаем, что рассчитывать физику мы должны каждые 20 миллисекунд. Поэтому в цикле мы просто проверяем, что если с момента последнего обновления физики прошло более чем 20 миллисекунд, то её нужно обновить.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
private const val TICKS_PER_SECOND = 50
private const val SKIP_TICKS = 1000 / TICKS_PER_SECOND
class GameLooper {
private var isRunning = true
fun loop() {
var nextGameTick = SystemClock.uptimeMillis()
while (isRunning) {
val needUpdate = SystemClock.uptimeMillis() > nextGameTick
if (needUpdate) {
processInput()
updatePhysics()
nextGameTick += SKIP_TICKS
}
updateRender()
}
}
}
Вывод изображения на экран с помощью updateRender мы делаем так часто, как можем. Теперь игра должна ощущаться плавнее, так как многие эффекты, шейдеры, частицы и пр. будут обрабатываться настолько быстро, насколько это возможно.
Но в играх время отрисовки кадров неодинаково, и может быть ситуация, когда какой-то кадр обрабатывался в updateRender сильно дольше обычного - к примеру 65 мс. Тогда обработка физики вместо того, чтобы выполниться 3 раза, выполнится всего один раз. В целом таких кадров может быть много. Из-за этого и так не слабенькое подтормаживание ощущается еще сильнее.
Поэтому надо научить физику “догонять”. Для этого мы вставим еще один цикл while, вместо if.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
private const val TICKS_PER_SECOND = 50
private const val SKIP_TICKS = 1000 / TICKS_PER_SECOND
class GameLooper {
private var isRunning = true
fun loop() {
var nextGameTick = SystemClock.uptimeMillis()
while (isRunning) {
while (SystemClock.uptimeMillis() > nextGameTick) {
processInput()
updatePhysics()
nextGameTick += SKIP_TICKS
}
updateRender()
}
}
}
Теперь новый кадр не будет отрисовываться, пока физика не догонит текущее время.
Пришло время разобраться с updateRender. Так как между вызовами updateRender физика может и не обновиться, то получится ситуация когда большая часть объектов в кадре не изменится. С этим нужно что-то сделать. Решение есть - интерполяция!
Допустим, с последнего обновления физики прошло 10 мс, время между обновлениями физики 20 мс. По сути мы просто делим 10 на 20 тем самым получив ½. То есть с последнего обновления физики прошла примерно половина времени кадра. ½ и будет нашим значением интерполяции. При отрисовке кадра мы можем например умножить вектора движений на это значение. Таким образом наша игра станет гораздо плавнее.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
private const val TICKS_PER_SECOND = 50
private const val SKIP_TICKS = 1000 / TICKS_PER_SECOND
class GameLooper {
private var isRunning = true
fun loop() {
var nextGameTick = SystemClock.uptimeMillis()
while (isRunning) {
while (SystemClock.uptimeMillis() > nextGameTick) {
processInput()
updatePhysics()
nextGameTick += SKIP_TICKS
}
val time = SystemClock.uptimeMillis() + SKIP_TICKS - nextGameTick
val interpolation = time.toFloat() / SKIP_TICKS
updateRender(interpolation)
}
}
}
Так, а разве у нас опять не возникнет проблема с погрешностью Float? Мы ведь опять что-то делим.
Вообще, так как минимальным шагом в наших вычислениях является миллисекунда, то в наихудшем случае мы будем делить 1 на 20. А 1/20 не очень страшная дробь. К тому же, updateRender лишь выводит изображение, и небольшая погрешность в нем навредит не так сильно, как в расчётах физики или положения объектов.
Последний вариант не является «серебрянной пулей» хоть и достаточно оптимален. В разных ситуациях могут пригодиться разные варианты циклов. Всё очень зависит от конкретной игры. Для соревновательных игр типа CS:GO или Valorant хочется обновлять мир и физику как можно чаще, на это и стоит делать упор. А также есть VR, в котором надо отрендерить не одну картинку, а две, причём не меньше 90 фпс, а лучше 120, иначе будет тошнить. А если уж в игре есть перемотка времени… В реальных игровых движках в таком цикле гораздо больше действий и итераций. Можете оценить как это выглядит в Unity. Если хотите поглубже погрузиться в океан главных циклов в играх, то вот хорошая статья и вот еще тоже.
Также мы не рассмотрели такой важный фактор, как постоянство кадровой частоты. Она тоже очень сильно влияет на ощущение плавности, но это отдельная и очень глубокая тема, для тех кто хочет в неё погрузиться, я тоже нашел хорошую статью (она ещё и с gif’ками!!!).
Полезные ссылки
Ссылки на оригинальные статьи:
Main Loop (Главный цикл) в Android Часть 1. Пишем свой цикл
Main Loop (Главный цикл) в Android Часть 2. Android SDK
Main Loop (Главный цикл) в Android Часть 3. Другие главные циклы